Manual de uso de WIPO Sequence
La finalidad de este documento es proporcionar instrucciones sobre cómo realizar operaciones básicas con la aplicación de escritorio WIPO Sequence. Normalmente, la herramienta está destinada a solicitantes de patente (o sus representantes) que desean presentar una solicitud de patente con una lista de secuencias.
El presente manual de uso corresponde a la versión 3.0.0 de WIPO Sequence.
1. Resumen de funciones
En el cuadro que figura a continuación se resumen todas las funciones que incorpora la herramienta en su versión actual, con enlaces a las secciones correspondientes:
2. Funciones de la herramienta
2.1 Vista inicial de proyectos
En esta sección se describen las distintas opciones disponibles en la vista inicial de proyectos.
Un proyecto es la estructura de objetos que la herramienta utiliza para almacenar los datos necesarios en la generación de una lista de secuencias. Una vez que se ha verificado que los datos almacenados en el proyecto se ajustan a la Norma ST.26 de la OMPI, la herramienta los utiliza como valores en la lista de secuencias generada.
En la vista inicial de proyectos se muestra la lista de los proyectos creados, y se da la opción de ordenarlos o de utilizar la función de búsqueda para filtrarlos por el nombre del proyecto, la referencia del expediente del solicitante, el nombre del solicitante, el título de la invención, el estado o la fecha de creación.
Nota: La herramienta puede mostrar un máximo de 1 000 proyectos. Si un proyecto no se muestra en la vista inicial de proyectos, se deberá utilizar la función de búsqueda para encontrar el proyecto por su nombre, dado que estará almacenado localmente aunque no aparezca en la vista inicial.
Crear proyecto
Para crear un proyecto, en primer lugar, hay que acceder a la vista inicial de proyectos que se muestra a continuación.

1) Habrá que hacer clic en el enlace "NEW PROJECT" en la parte superior de la vista. Como se muestra, la herramienta solicitará un nombre (obligatorio) y una descripción (opcional).

2) Cuando se introduzca un valor en el campo del nombre, se activará el botón "Save" para que se pueda guardar el proyecto nuevo. Ese proyecto creado aparecerá en la lista de proyectos en la vista inicial de proyectos.
Importar proyecto
Esta función permite importar a la herramienta un proyecto previamente exportado. Para importar un archivo de proyecto, se deberá acceder a la vista inicial de proyectos.
Hay que hacer clic en el enlace “IMPORT PROJECT” situado en la parte superior de la vista y seguir los pasos que se muestran en el siguiente vídeo:
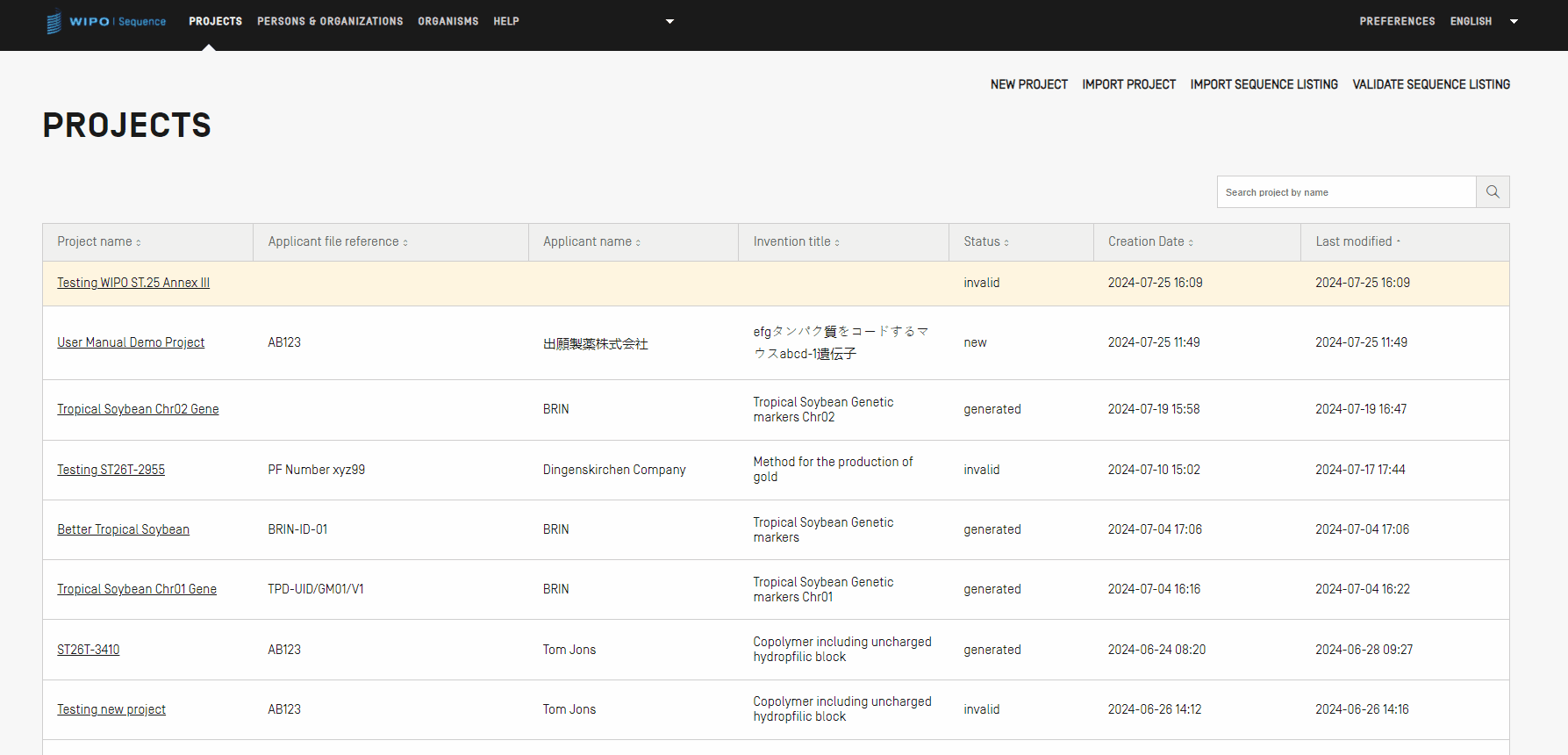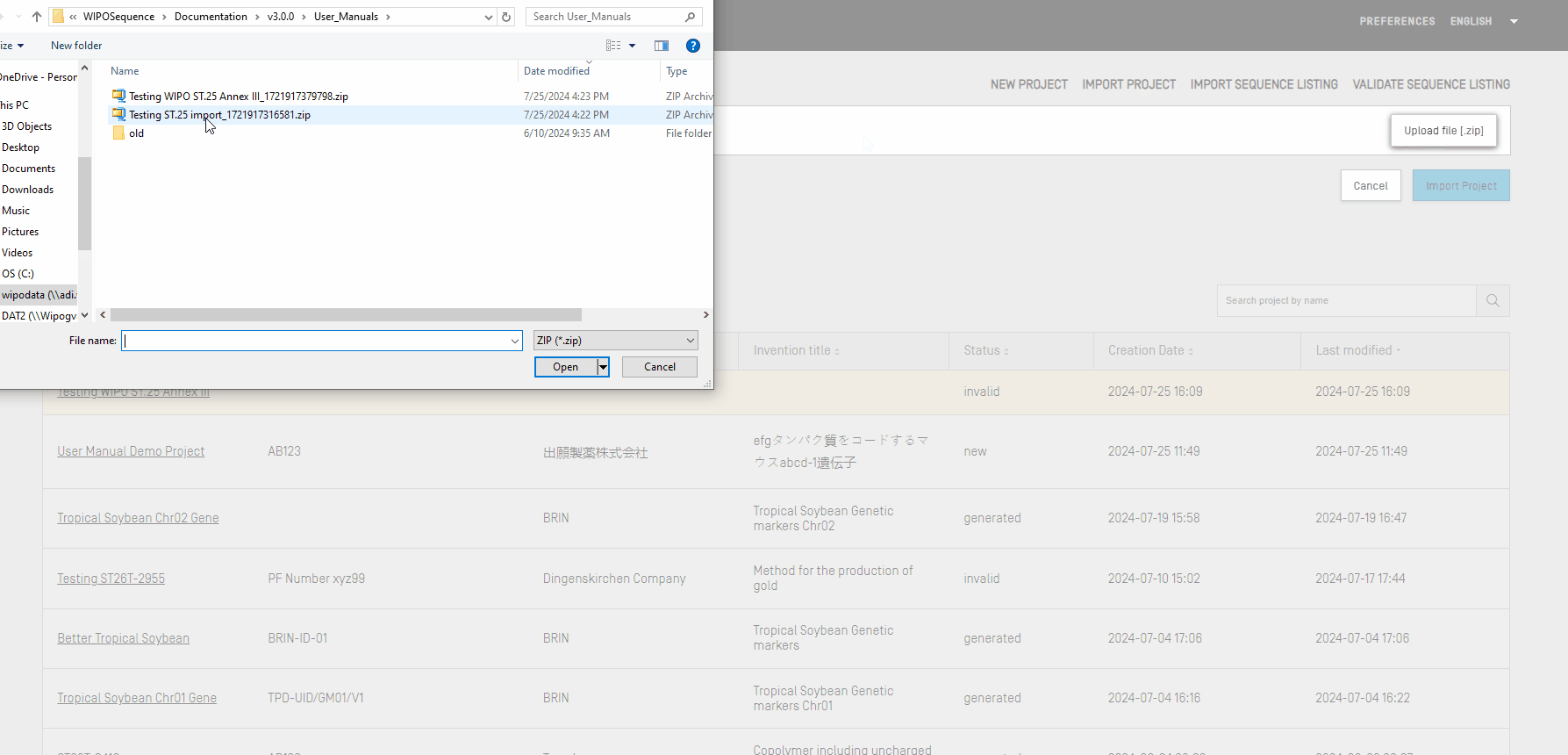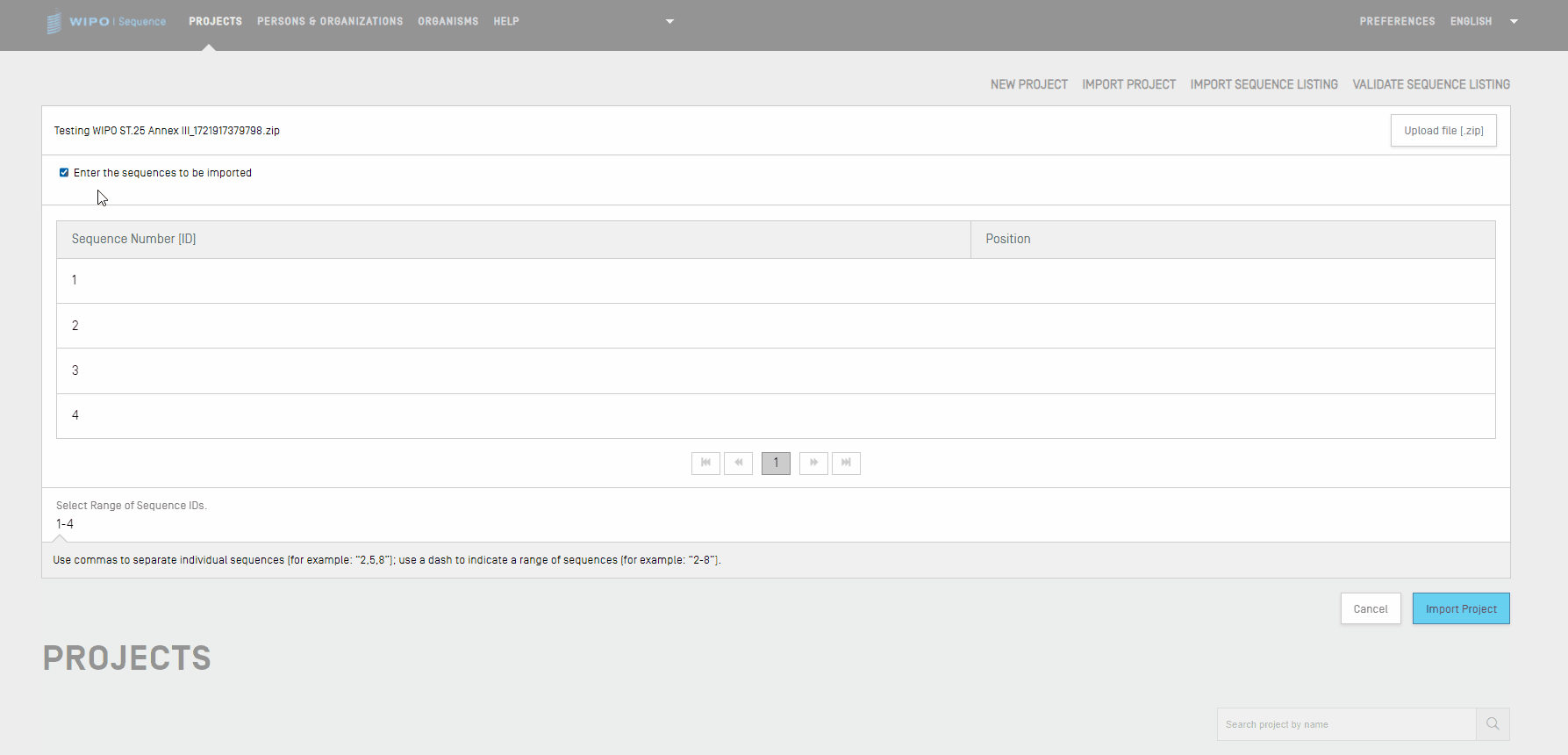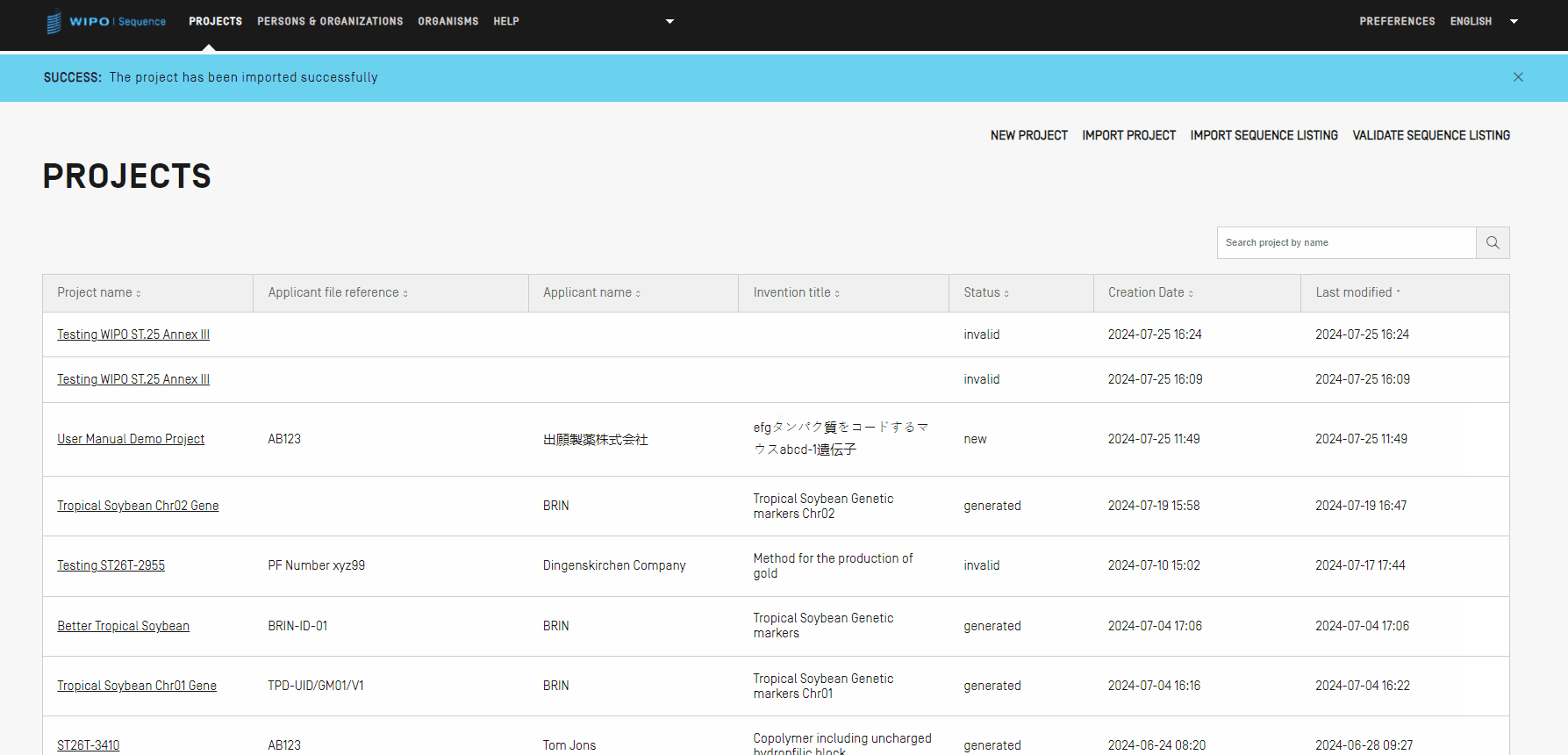
Si la casilla de verificación de “Select Range Sequences” no se marca, se importarán todas las secuencias. Para seleccionar las secuencias que se desean importar al proyecto, se deberá marcar la casilla de verificación de “Select Range Sequences” e introducir los identificadores de dichas secuencias en el campo correspondiente. Se puede indicar una sola secuencia, una lista de secuencias mediante sus respectivos identificadores separados por comas o un intervalo de secuencias utilizando el formato x-y para introducir sus identificadores. Por defecto, el número total de secuencias del proyecto importado se mostrará como un intervalo, es decir, 1–número total de secuencias.
Ejemplo: “1, 3, 7, 13-20, 30-50”.
Si el proyecto se importa correctamente, aparecerá el siguiente mensaje sobre fondo azul en la parte superior de la vista.
Nota: Es necesario verificar que el proyecto importado en formato zip se corresponda con la base de datos actual. Si el proyecto se exportó en una versión anterior a la 3.0.0, no funcionará correctamente; el proyecto importado debe utilizar la misma base de datos. Esto se debe a la nueva implementación de la base de datos de la versión 3.0.0 en adelante.
Importar lista de secuencias
Desde la vista inicial de proyectos, se puede importar información de secuencias exclusivamente desde una lista de secuencias generada con arreglo a la Norma ST.26 o ST.25. Los archivos tendrán la extensión xml para el formato de la Norma ST.26 y txt para el de la Norma ST.25. En el vídeo que figura a continuación se puede obtener más información sobre los pasos que hay que seguir.

Nota: Cuando se importa una lista de secuencias, las características y los calificadores distinguen entre mayúsculas y minúsculas y deben ajustarse a los valores que figuran en el Anexo I de la Norma ST.26 de la OMPI.
También es importante tener en cuenta que las listas de secuencias conformes con la Norma ST.25 deben ser válidas; de lo contrario, no se puede garantizar que WIPO Sequence realice adecuadamente la importación.
El cuadro de informe de importación solo se mostrará cuando se producen errores en la importación de un archivo e incluirá los siguientes datos distribuidos en columnas:
- Tipo de nota: “INDIVIDUAL” si el mensaje se refiere a una secuencia concreta o “GLOBAL” si se trata de un mensaje genérico que se refiere a una o varias secuencias.
- Código de elemento de datos: del archivo de origen, para las listas de secuencias en el formato de la Norma ST.25.
- Mensaje: mensaje con información detallada sobre el problema identificado y los cambios hechos para solucionarlo (de haberse realizado alguno).
- Secuencia afectada: identificador de la secuencia importada a la que se refiere el mensaje (cuando el tipo de nota es “INDIVIDUAL”; de lo contrario este campo aparece en blanco).

Si el archivo tenía formato ST.25, la vista de informe de importación incluirá en primer lugar un informe de importación, así como un informe de datos modificados. En el informe de datos modificados se muestran los datos que han sido objeto de transformación o modificación durante el proceso de importación. En un cuadro resumen se presentan los siguientes datos:
- Etiqueta de origen: código de elemento de datos que indica el tipo de elemento, cuando se importan listas de secuencias generadas con arreglo a la Norma ST.25 de la OMPI
- Nombre del elemento de origen: nombre correspondiente al tipo de elemento
- Valor del elemento de origen: valor correspondiente al elemento de origen en el archivo de origen
- Nombre del elemento final: nombre equivalente del elemento en el formato de la Norma ST.26 en el que se almacenará la información en el proyecto
- Valor del elemento final: valor que se establecerá para el nombre del elemento final en el proyecto
- Transformación: descripción de las modificaciones o transformaciones realizadas en el elemento
- Identificador de secuencia: identificador de la secuencia correspondiente del elemento transformado en el proyecto

Se puede volver a la vista inicial de proyectos o descargar un informe de las modificaciones en formato PDF. Para obtener instrucciones sobre cómo descargar el archivo PDF, véase la sección Visualizar la lista de secuencias.
El proceso de importación puede fallar si hay errores en el archivo de la lista de secuencias. En ese caso, tras el intento de importación, aparecerá un mensaje sobre fondo rojo para indicar que se ha producido un error durante la importación.

Nota: La herramienta funciona de manera óptima con un máximo de 100 000 secuencias. En el caso de listas de secuencias de gran tamaño, se puede recurrir a la siguiente solución: dividir el proceso de importación en una serie de etapas en las que se seleccione un intervalo específico de secuencias para su importación e importar las secuencias de cada uno de esos intervalos a un proyecto. Por ejemplo, una lista de 100 000 secuencias se puede dividir en 10 series de 10 000 secuencias, y cada serie se puede importar por separado. Las primeras 10 000 secuencias se utilizarían para crear el proyecto.
Validar lista de secuencias
Se puede validar un archivo de lista de secuencias en formato ST.26 haciendo clic en el enlace “VALIDATE SEQUENCE LISTING” que aparece en la parte superior derecha de la vista de proyectos.

Si la lista de secuencias pasa la validación, aparecerá el siguiente mensaje sobre fondo azul:

Si la lista de secuencias no supera la validación, se abrirá un informe de verificación en el navegador que incluirá un cuadro con los errores de validación, como se muestra en el ejemplo del vídeo. La ubicación del archivo HTML se mostrará junto con el informe de verificación en formato XML, lo que permite acceder a los archivos y copiarlos en una ubicación diferente.
Si se utiliza el navegador Internet Explorer, para que las secuencias se carguen correctamente en el formato de visualización predeterminado, debe permitirse la ejecución de un archivo de órdenes interno en la computadora. De lo contrario, las secuencias no se visualizarán adecuadamente.
Conviene tener en cuenta que, para poder validar una lista de secuencias, el archivo en formato ST.26 ha de cumplir los siguientes requisitos:
-
Deberá estar codificado en formato UTF-8 y contener caracteres válidos de acuerdo con la especificación XML 1.0.
-
Deberá contener una línea de declaración de tipo de documento (DOCTYPE) como la siguiente:
<!DOCTYPE ST26SequenceListing PUBLIC "-//WIPO//DTD Sequence Listing 1.3//EN" "ST26SequenceListing_V1_3.dtd">
El archivo deberá ser compatible con el archivo de definición de tipo de documento ST26SequenceListing_V1_3.dtd.
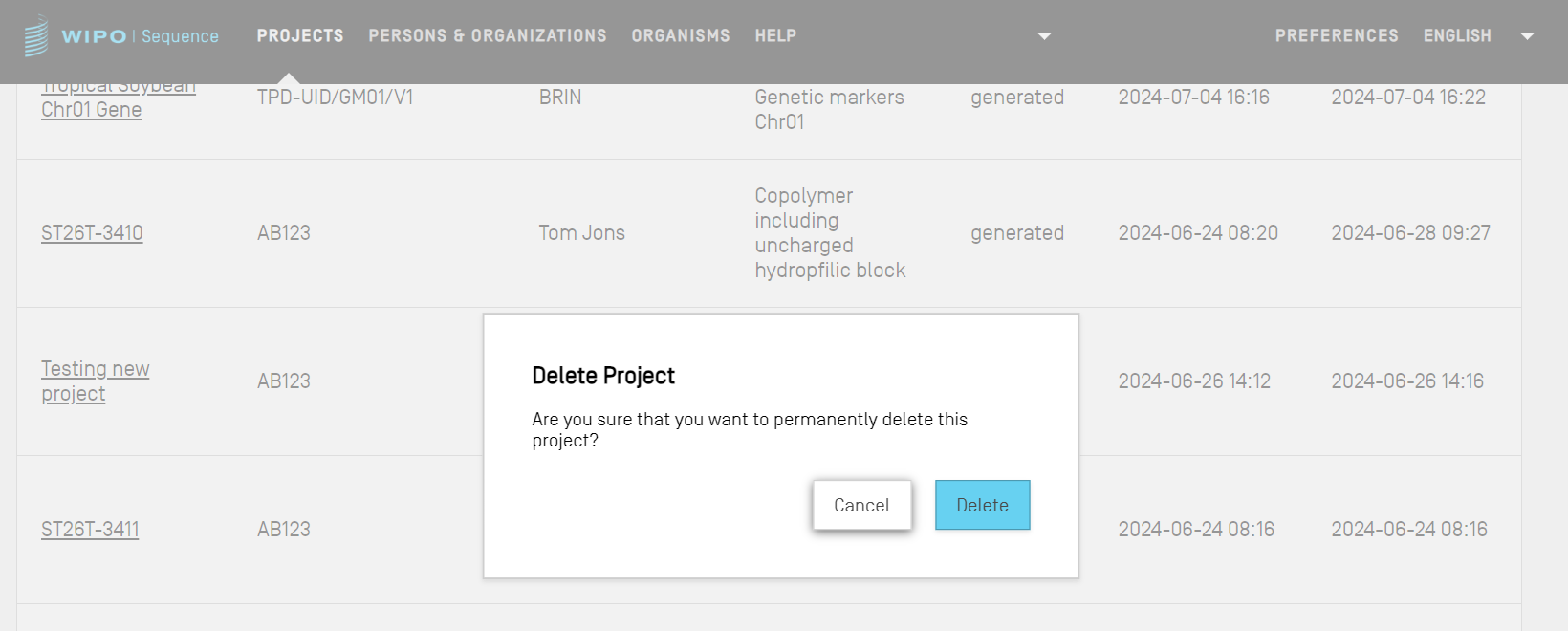
Eliminar proyecto
Para eliminar un proyecto, habrá que acceder a la vista inicial de proyectos.

Se deberá hacer clic en el botón con el icono de la papelera de la fila del cuadro de la vista de proyectos correspondiente al proyecto que se desea eliminar.
En la ventana emergente, habrá que hacer clic en “Delete” para confirmar que se desea eliminar el proyecto seleccionado.
2.2 Vista de datos de proyecto
La vista de datos de proyecto incluye toda la información relativa a una solicitud de patente o a una lista de secuencias. Está dividida en dos secciones: información general y datos de la secuencia. En la parte superior se muestra un cuadro con información básica sobre el proyecto, que incluye:
- El nombre del proyecto
- La fecha y hora de creación del proyecto
- La fecha y hora de las últimas modificaciones realizadas en el proyecto
- El estado del proyecto (valores posibles: "nuevo", "modificado", "generado", "no válido", "válido", "advertencias"): este campo no se puede editar
- La descripción del proyecto: opcional
- El nombre del archivo importado (en caso de que el proyecto se haya importado)
- El código de idioma de texto libre de origen
- El número de secuencias (en el campo "Sequences")
- Un campo que indica si está activada la adición automática de un calificador "translation" cuando se crea una característica "CDS" (función a nivel de proyecto)
- El código de idioma de texto libre distinto del inglés

Hay dos niveles de menús, el primero corresponde a la vista de datos de proyecto (en amarillo) y el segundo es un menú de navegación para acceder a otras vistas relacionadas con el proyecto (en azul). Se puede salir del proyecto haciendo clic en “Return to project home”.
A través del menú de navegación de la página de datos de proyecto se puede acceder a las siguientes seis vistas:
- La vista de datos de proyecto, mediante el enlace que utiliza el nombre del proyecto
- La vista de informe de verificación, en la que se puede acceder al informe de verificación
- La vista de calificadores dependientes del idioma, en la que se puede acceder a los calificadores de texto libre dependientes del idioma y exportarlos o importarlos
- La vista de informe de importación, que permite acceder al informe de importación
- La vista de visualización de lista de secuencias, que permite acceder a los formatos legibles por personas de las listas de secuencias generadas con arreglo a la Norma ST.26
- El menú de ayuda, que incluye referencias al manual de uso y a la base de conocimientos de WIPO Sequence y la Norma ST.26
- La vista de preferencias, que en la presente versión de WIPO Sequence se aplica a todos los proyectos
Imprimir proyecto
Se puede imprimir un proyecto específico accediendo a la correspondiente vista de datos de proyecto y haciendo clic en el botón “Print” situado en la parte superior de dicha vista.
A continuación, aparecerán dos casillas de verificación para seleccionar la información que se desea imprimir del proyecto: información general o datos de la secuencia.

Si se selecciona “Print Sequences”, se podrá especificar qué secuencias se desean imprimir indicando el intervalo de identificadores en el campo “Sequence IDs”, o simplemente imprimirlas todas si se deja ese campo en blanco.
Por defecto, aparecerá el intervalo correspondiente al número total de secuencias del proyecto.
Exportar proyecto
Se podrá exportar cualquier proyecto a un archivo .zip para tener una copia de seguridad de los datos del proyecto o, si se desea, para importarlo en otra instancia de WIPO Sequence instalada en otra computadora. Simplemente hay que hacer clic en el botón “Export” y seleccionar una ubicación para guardar el archivo .zip. Si la exportación se realiza correctamente, aparecerá el siguiente mensaje sobre fondo azul:

Importar un proyecto a otro
Se podrá copiar en el proyecto que esté abierto información de otros proyectos almacenados en la herramienta. La información importada podrá proceder de la sección Información general, la sección Secuencias, o de ambas. La información general importada reemplazará la información general del proyecto abierto, mientras que las secuencias importadas se añadirán a la lista de secuencias del proyecto.

Primero hay que seleccionar en el menú desplegable el proyecto del que se desea importar información. Se puede marcar la casilla de verificación para incluir datos de la sección Información general del proyecto y también introducir un intervalo de identificadores de secuencia para especificar las secuencias que se importarán al proyecto en curso. Por defecto, aparecerá el intervalo correspondiente al número total de secuencias del proyecto.
Si se marca la casilla de verificación de información general, aparecerá un cuadro con toda la información general de ambos proyectos: el proyecto seleccionado (proyecto de destino) y el proyecto importado (proyecto de origen). A continuación, habrá que seleccionar los datos de información general que serán reemplazados por los correspondientes del proyecto importado.
Por último, una vez que se han seleccionado los datos de información general y las secuencias que se desean importar al proyecto, se deberá hacer clic en el botón azul “Import Project”. Aparecerá un mensaje sobre fondo azul para indicar que la importación se ha realizado correctamente.
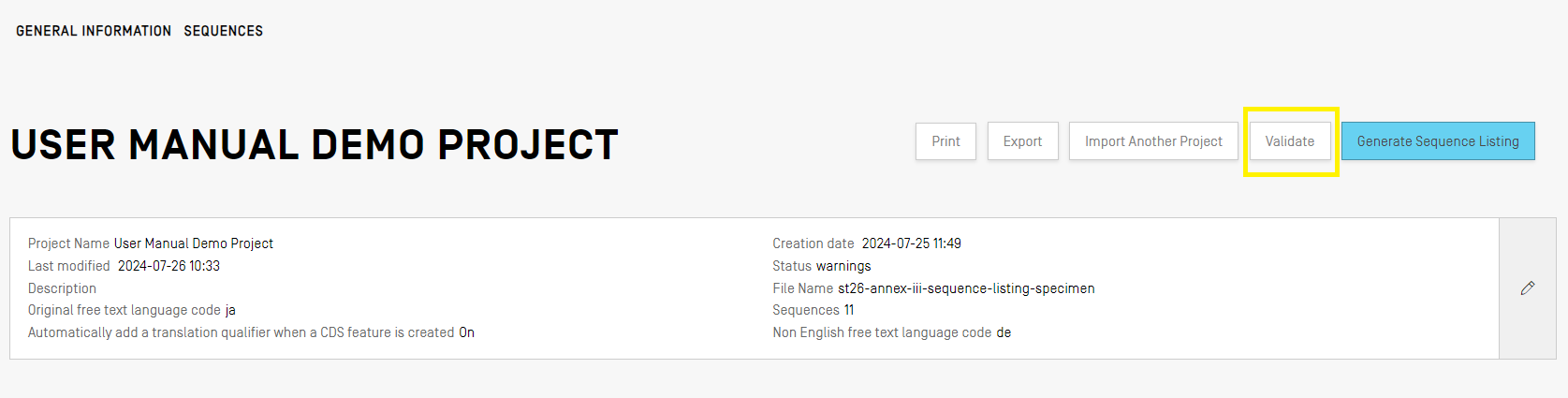
Validar proyecto
Antes de generar la lista de secuencias en un archivo XML con arreglo a la Norma ST.26, el proyecto se someterá a una prueba de validación. Este paso se realiza siempre antes de generar la lista de secuencias, pero también puede realizarse en cualquier otro momento.
Para validar un proyecto, hay que hacer clic en el botón “Validate” situado en la parte superior de la vista de datos de proyecto.
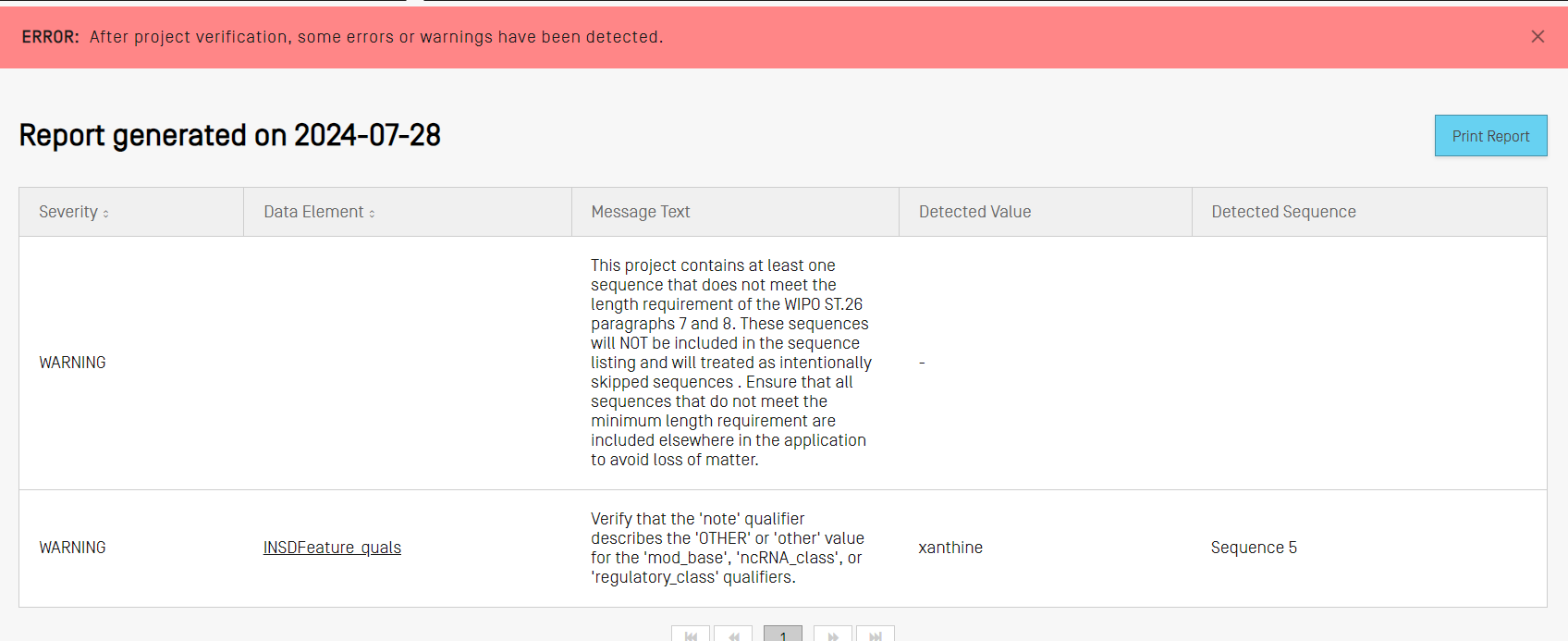
Una vez finalizada la validación, se accederá a la vista de informe de verificación en la que se mostrarán los errores o advertencias de verificación que se hayan podido producir. Aparecerá un mensaje sobre fondo azul si el resultado de la validación es satisfactorio.
Si durante el proceso de validación se producen errores o advertencias, se generará un informe de verificación que incluirá un cuadro con las normas y directrices de verificación que se han incumplido. En cada fila del cuadro se indica si se trata de un error, que deberá resolverse, o de una advertencia, que podrá ser ignorada.
Generar una lista de secuencias
Una última acción, y quizás la más importante, que se puede realizar para un proyecto concreto consiste en generar la lista de secuencias. Para ello, se deberá hacer clic en el botón azul “Generate Sequence Listing”, situado en la parte superior de la vista de datos de proyecto. Automáticamente se iniciará el proceso de validación del proyecto, que se realizará antes de generar la lista.
Si el proyecto pasa la validación, se abrirá un cuadro de diálogo para seleccionar la ubicación en la que se desea guardar el archivo XML de la lista de secuencias generada de conformidad con la Norma ST.26.
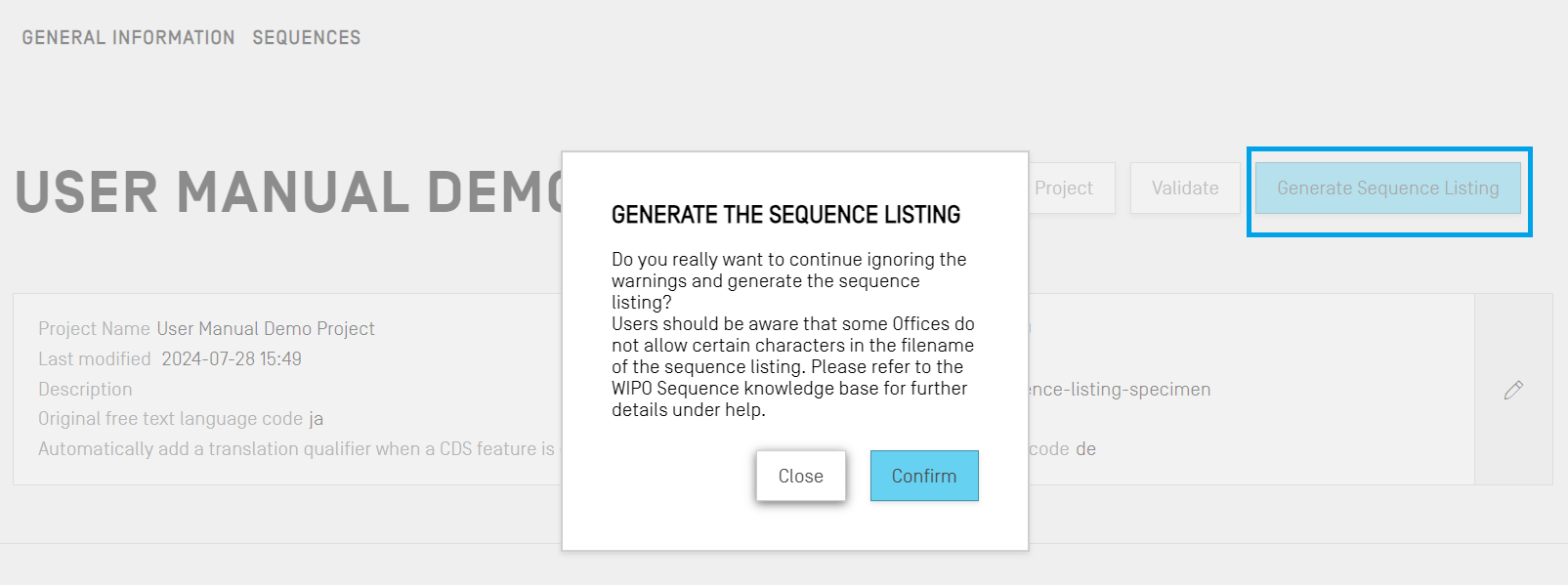
Si el proyecto no supera la validación, se mostrará la vista de informe de verificación junto con un mensaje sobre fondo rojo. Un mensaje sobre fondo azul indicará que el proyecto ha pasado la validación.
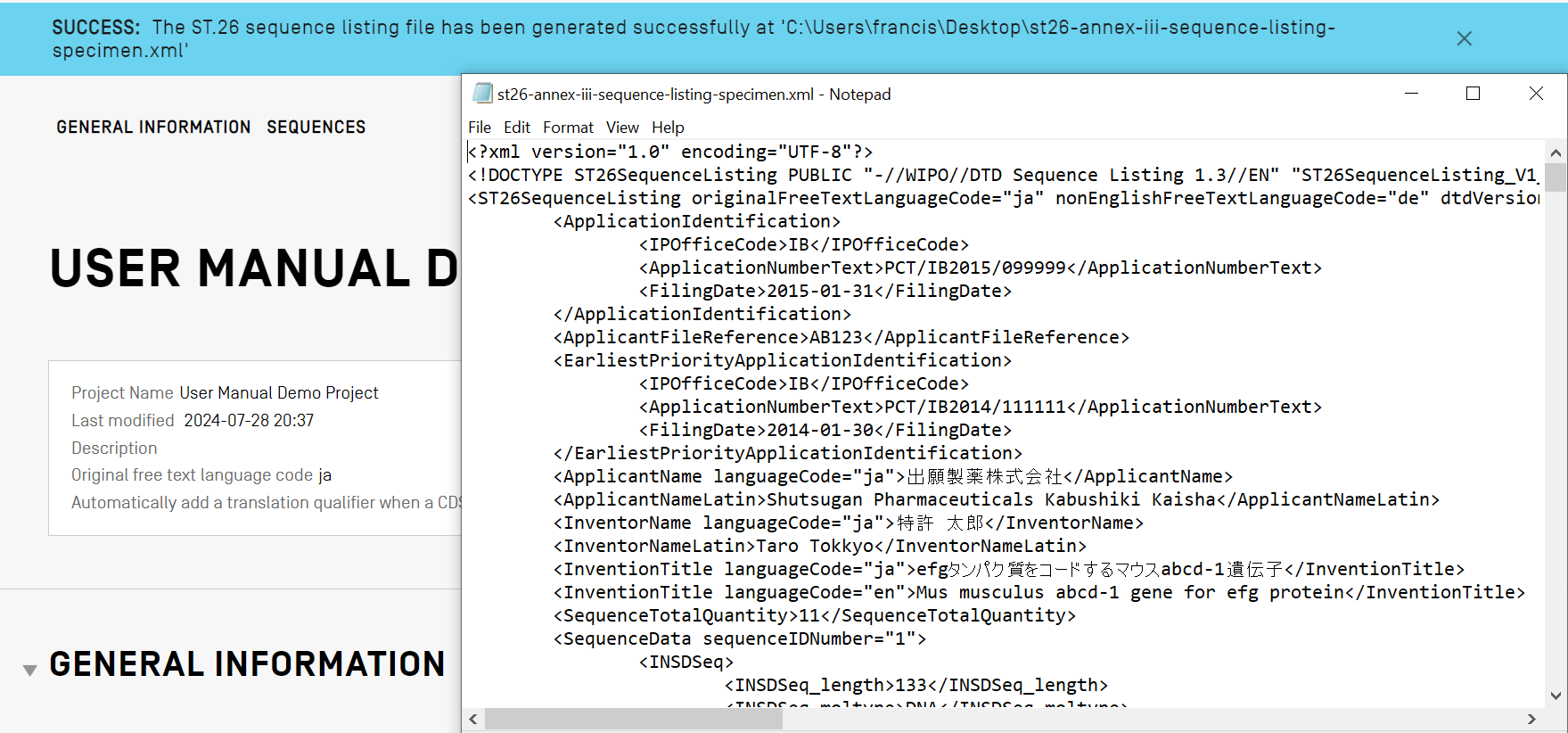
Visualización de lista de secuencias
WIPO Sequence permite generar la lista de secuencias en un formato más fácil de leer para las personas que el formato XML. Una vez generada la lista de secuencias, el archivo XML puede visualizarse en formato HTML o exportarse como archivo de texto. Utilizando cualquier navegador de Internet, también se puede guardar la lista de secuencias mostrada en formato HTML como un archivo PDF. Se puede acceder a la función de exportación desde la vista de visualización de lista de secuencias.
Si para un proyecto determinado la lista de secuencias no se genera correctamente, en la vista de visualización de lista de secuencias se desactivarán los botones “Display Sequence Listing” y “Export Sequence Listing as .txt file" y se mostrará un mensaje de error.
Calificadores de texto libre dependientes del idioma
Los calificadores que permiten un valor de texto libre en un proyecto aparecen en la vista de calificadores dependientes del idioma de la página del proyecto. Cualquier calificador dependiente del idioma que se añada al proyecto en cuestión se mostrará también en esa vista.
Se puede modificar un valor de texto libre traducido asociado a un calificador haciendo clic en el valor del “Qualifier Name”, lo que abrirá una superposición con un panel de edición debajo del cuadro.
Es necesario proporcionar el código de idioma de origen y el código de idioma de destino para la exportación de archivos XLIFF con los calificadores de texto libre. Los traductores deberán suministrar los valores traducidos antes de reimportar el archivo XLIFF.
El valor del calificador traducido, que aparece en la columna “Non-English Qualifier Value", corresponde al idioma seleccionado especificado por el código de idioma de texto libre distinto del inglés.
Si se hace clic en el botón “IMPORT FREE-TEXT QUALIFIERS”, la herramienta abrirá el explorador de archivos y se podrá buscar y seleccionar el archivo XLIFF que se desea importar. La validación se realiza en varias etapas para garantizar las asociaciones adecuadas entre los valores en el idioma de origen y en el idioma de destino.
Importar calificadores de texto libre desde un archivo XLIFF
El archivo seleccionado debe estar en formato XLIFF y contener los siguientes elementos de datos:
- Nombre del proyecto
- El código de idioma de destino
- El código de idioma de origen
- Para cada elemento de la unidad XLIFF:
- El identificador único del calificador (formato: un número precedido de la letra “q”)
- El valor del calificador en la etiqueta del idioma de origen
- El valor del calificador en la etiqueta del idioma de destino
Una vez que se haya confirmado el archivo seleccionado para su importación, la herramienta preguntará si se desea continuar con el proceso mediante la confirmación de una serie de etapas de verificación:
- El sistema compara el nombre del proyecto contenido en el archivo de entrada con el nombre del proyecto seleccionado.
- El sistema indicará si no se ha podido asociar algún calificador.
- El sistema indicará las modificaciones relativas al idioma de origen y a los valores de los calificadores.
- El sistema indicará las modificaciones relativas al idioma de destino y a los valores de los calificadores traducidos.
Una vez completadas esas etapas, aparecerá en la parte superior, sobre fondo azul, el mensaje “SUCCESS: THE FREE-TEXT QUALIFIER HAS BEEN IMPORTED SUCCESSFULLY”, así como un informe de importación con los valores previos y actuales importados para los calificadores de texto libre dependientes del idioma. Se puede regresar a la vista de calificadores de texto libre haciendo clic en “RETURN TO FREE TEXT QUALIFIERS”.
Exportar calificadores de texto libre en formato XLIFF
Si se hace clic en el botón “EXPORT FREE TEXT QUALIFIERS” en la parte superior de la vista y, a continuación, en el cuadro de diálogo se selecciona el nombre de archivo y la ubicación para guardar el archivo de texto de los calificadores, se exportarán todos los calificadores de texto libre del proyecto y se guardarán en un archivo con formato XLIFF.
El archivo incluirá:
- El idioma de origen del proyecto
- El idioma de destino del proyecto
- Los calificadores de texto libre
- Los valores traducidos de los calificadores de texto libre
- La información del calificador y la característica asociados incluidos en el cuadro
Este archivo XLIFF puede visualizarse, editarse e importarse de nuevo en la herramienta una vez que se introduzcan los valores traducidos correspondientes.
Introducir datos de un proyecto
Un proyecto se divide en dos secciones, al igual que la lista de secuencias generada: información general y datos de la secuencia. Se pueden cortar y pegar datos en un proyecto o importar datos de otro proyecto o lista de secuencias. Por lo general, al hacer clic en el icono del lápiz se podrán editar los campos del proyecto. El asterisco (*) indica los campos que son obligatorios.
Información general
En la sección Información general se podrá introducir información relativa a la solicitud de patente, que se utilizará para asociar la lista de secuencias generada con dicha solicitud. La primera subsección, Identificación de la solicitud, está relacionada con el estado y la información de la solicitud de patente del proyecto seleccionado. A continuación se indica la información que debe facilitarse en cada subsección.
Subsección 1: Identificación de la solicitud
Para editar la información dentro de la subsección Identificación de la solicitud, hay que hacer clic en el icono del lápiz que aparece a la derecha del cuadro de la subsección. A continuación, se deberá proporcionar la información que se indica a continuación:
- Si ya se ha asignado un número de solicitud, se deberá seleccionar el código de la Oficina de propiedad intelectual (PI) en la que se presentó la solicitud. Se trata del código de la Norma ST.3 de la OMPI.
- Habrá que indicar, marcando el botón de opción correspondiente, si ya se ha recibido un número de solicitud o si se ha facilitado la referencia de expediente del solicitante.
- En caso de no disponer del número de solicitud, se DEBE proporcionar en este campo la referencia de expediente del solicitante.
- Deberá introducirse el número de solicitud, si ya se ha asignado uno.
- La fecha de presentación de la solicitud, si se ha fijado una, se seleccionará con el selector de fechas.
- Por último, se hará clic en el botón azul “Save”.
En el ejemplo mostrado, también se han introducido todos los valores opcionales:

Nota: Aunque se introduzcan los valores obligatorios, siempre aparecerá una advertencia en el informe de verificación en la que se indica que falta el número de identificación de la solicitud y que dicho número es obligatorio si se ha asignado.
Subsección 2: Solicitud de prioridad
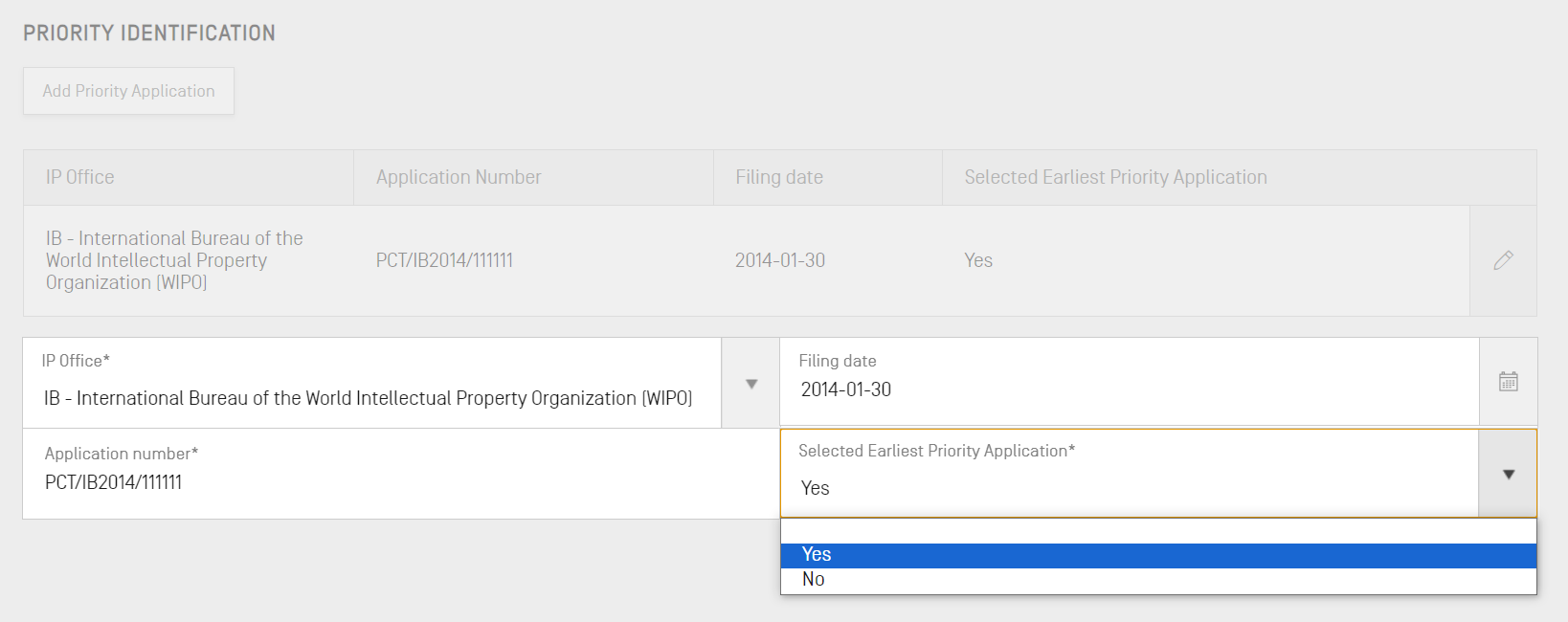
Si existe una solicitud de prioridad asociada a la solicitud del proyecto seleccionado, se introducirán los datos correspondientes en la subsección Solicitud de prioridad. Para añadir una solicitud de prioridad al proyecto, se deberá hacer clic en el botón “Add Priority Identification” en la sección Información general.
Para establecer la solicitud de prioridad seleccionada como la más antigua, se deberá elegir “Yes” en el menú desplegable del campo “Selected Earliest Priority Application”. De esta manera se establecerá, o modificará, la solicitud de prioridad seleccionada como la más antigua cuando se genere la lista de secuencias. Para finalizar, habrá que hacer clic en el botón azul “Add Earliest Priority Application”.
Subsección 3: Solicitante/inventor
Para añadir al proyecto datos relativos a un nuevo solicitante o inventor, habrá que hacer clic en el botón “Add Inventor” o “Add Applicant” de la sección Información general de la vista de datos de proyecto. Los pasos en ambos casos son idénticos, por lo que el proceso se describe de forma general, y deberá realizarse dos veces si se tiene que incluir tanto un solicitante como un inventor en el proyecto, aunque el solicitante sea el inventor.
Al hacer clic en el botón correspondiente, se abrirá una superposición con dos botones de opción. Si se selecciona “Existing applicant/inventor”, se podrá elegir en el menú desplegable entre las personas y organizaciones guardadas en la instancia local de la herramienta de escritorio.
Si se selecciona “New applicant/inventor”, habrá que rellenar los datos necesarios para introducir una nueva persona u organización.
Una vez introducida la información, habrá que hacer clic en el botón “Add Applicant” o “Add Inventor”.

Nota: Solo se requiere un solicitante para que la lista de secuencias se considere válida. Se debe marcar un solicitante o inventor como principal. Será el solicitante o inventor que aparecerá en la lista de secuencias generada.
Subsección 4: Título de la invención
Por último, habrá que añadir un título de la invención en la sección Información general.
Para añadir un nuevo título de la invención:
- Hay que hacer clic en el botón “Add Invention title”.
- En la superposición que aparece, hay que introducir el título de la invención e indicar también el idioma en el que se proporciona el título.
- Por último, se deberá hacer clic en el botón azul “Añadir título de la invención”.

De acuerdo con la Norma ST.26 de la OMPI, el título de la invención debe proporcionarse obligatoriamente en el idioma de presentación de la solicitud. No obstante, un proyecto puede incluir opcionalmente más de un título de invención en diferentes idiomas, pero solo un título de invención por idioma. Cada nuevo título de invención puede añadirse siguiendo los pasos anteriores.
Datos de la secuencia
En la sección Secuencias de la vista de datos de proyecto se puede introducir información técnica relativa a las secuencias. WIPO Sequence ofrece varias opciones para introducir datos de secuencias en un proyecto, incluidas la creación de manera manual, la importación y la adición de una secuencia. En las subsecciones siguientes se explican los pasos que hay que seguir para realizar esas acciones.
Crear una secuencia
Los pasos para crear una secuencia en el proyecto son los siguientes:
- Haga clic en el botón para crear una secuencia. Se activará el panel de la secuencia.
- Asigne un nombre a la secuencia escribiéndolo en el campo correspondiente. También puede dejar el campo relativo al nombre de la secuencia en blanco y WIPO Sequence asignará un nombre predeterminado a la secuencia. Los nombres predeterminados comienzan con "Seq" y, a continuación, un número que aumenta progresivamente ("Seq_1", "Seq_2", "Seq_3").
Nota: El propósito del nombre de la secuencia es solo facilitar la distinción entre secuencias dentro del proyecto; este nombre no aparecerá en el archivo XML de la lista de secuencias.
- Utilice el cuadro desplegable "Tipo de molécula*" para seleccionar uno de los tres tipos de moléculas permitidos por la Norma ST.26 ("ADN", "ARN", "AA"). Si desea crear una secuencia con segmentos de "ADN" y "ARN", se debe seleccionar "ADN" como tipo de molécula.
- Escriba o pegue los residuos de la secuencia en el campo correspondiente.
- Escriba o pegue el nombre del organismo de origen en el campo "Nombre del organismo*". Para seleccionar el nombre de un organismo en la lista predefinida, simplemente comience a escribir el nombre del organismo y aparecerá una lista desplegable. Seleccione el nombre del organismo, si está presente. De lo contrario, es posible que la herramienta le pida que agregue el organismo a la base de datos de organismos almacenada localmente.
- Si el tipo de molécula es ADN o ARN, debe seleccionar un tipo de molécula específico en el cuadro desplegable correspondiente al calificador del tipo de molécula, que se rellenará con los valores adecuados para el tipo de molécula seleccionado en el paso 3. Tenga en cuenta que si el tipo de molécula es AA, el calificador se rellenará automáticamente con el valor de "proteína".
- Si se selecciona la casilla para marcar la secuencia como omitida intencionadamente, la secuencia se incluirá en el archivo XML de la lista de secuencias como secuencia omitida intencionadamente, es decir, tendrá el formato especificado en el párrafo 58 de la Norma ST.26 de la OMPI. Tenga en cuenta que la casilla para marcar una secuencia como omitida intencionadamente debe estar seleccionada para guardar una secuencia con menos de 10 residuos de nucleótidos distintos de "n" o menos de 4 residuos de aminoácidos distintos de "X". Cuando se omite una secuencia intencionadamente, el panel de la secuencia eliminará todas las restricciones sobre el suministro de valores para los elementos obligatorios y no se tendrá en cuenta la secuencia guardada al validar el proyecto.
- Si el tipo de molécula de la secuencia es ADN, aparecerá un cuadro indicando que la secuencia contiene fragmentos de ADN y ARN. Si la secuencia contiene fragmentos de ADN y ARN, al marcar esta casilla se pueden añadir fácilmente las características exigidas por la Norma ST.26 de la OMPI, párrafo 55, para describir híbridos de ADN/ARN. Al marcar la casilla que indica que la secuencia contiene fragmentos de ADN y ARN, el panel de la secuencia se ampliará para incluir campos que permitan describir cada fragmento de ADN y ARN con la clave de caracterización «misc_feature» y la ubicación correspondiente. Para cada fragmento, seleccione ADN o ARN en el menú desplegable del campo relativo al tipo de molécula y, a continuación, introduzca una ubicación en el campo correspondiente. También se puede incluir texto en el campo de texto adicional. Se pueden crear tantas de esas características como sea necesario haciendo clic en el botón para añadir una característica "misc_feature". Tenga en cuenta que toda la longitud de la secuencia debe estar cubierta por claves de caracterización "misc_feature", de modo que cada residuo quede indicado como ADN o ARN.
- Para finalizar y guardar la secuencia, haga clic en el botón gris para crear la secuencia o en el botón azul para crear y mostrar la secuencia. Al hacer clic en el botón azul, se abrirá una pantalla desplegable de la secuencia creada para poder revisar los valores. Estará visible en la vista de detalles del proyecto, debajo de la sección de secuencias.
Nota: Si la secuencia es de nucleótidos (ADN o ARN), solo se permiten los símbolos que figuran en el Anexo I, cuadro 1, de la Norma ST.26 de la OMPI (a, c, g, t, m, r, w, s, y, k, v, h, d, b, n). Tenga en cuenta que el símbolo "u" no está permitido. Los símbolos introducidos como letras mayúsculas se convertirán en letras minúsculas. Los símbolos que no sean letras se eliminarán automáticamente (espacios, números, *, -, etc.)
Si la secuencia es de aminoácidos (AA), solo se permiten los símbolos que figuran en el Anexo I, cuadro 3, de la Norma ST.26 de la OMPI (A, R, N, D, C, Q, E, G, H, I, L, K, M, F, P, O, S, U, T, W, Y, V, B, Z, J, X). Tenga en cuenta que solo se permiten símbolos de aminoácidos de una letra. Si la secuencia de aminoácidos está representada por símbolos de aminoácidos de tres letras (por ejemplo, Met-Arg-Leu-Trp-Ile), primero debe convertirse en símbolos de una letra antes de escribirla o pegarla en el campo correspondiente a los residuos.
La secuencia creada aparecerá en la última posición de la lista de secuencias, y se le asignará el siguiente número de identificador de secuencia disponible. Para reordenar la posición de una secuencia en la lista, hay que seguir estos pasos.
Importar secuencia
Las secuencias también pueden ser importadas al proyecto desde un archivo. Los formatos de archivo aceptados se indican en la sección 3. Cuando se seleccione un archivo, la herramienta de escritorio detectará automáticamente su formato.
- Para empezar, se deberá hacer clic en el botón “Import sequence”.
- A continuación, habrá que hacer clic en el botón "Upload file [.txt, .xml]". Al abrirse el cuadro de diálogo, se seleccionará el archivo que contiene los datos de la secuencia que se desea importar. La herramienta de escritorio detectará el formato del archivo y realizará algunas comprobaciones de validación durante la importación. La herramienta admite cinco formatos para importar secuencias a un proyecto: formato RAW, formato de varias secuencias, formato FASTA, formato ST.26 y formato ST.25.
- En caso de que se seleccione un archivo que esté en formato ST.25 o ST.26 de la OMPI, se mostrará en primer lugar la casilla de verificación “Select Range Sequences”. Al marcarla, se abrirá un cuadro con los identificadores de las secuencias contenidas en el archivo y el orden en que estas serán añadidas a la lista de secuencias del proyecto. Si no se desea importar todas las secuencias al proyecto, se puede indicar un intervalo determinado de identificadores de secuencia. Se puede indicar una sola secuencia, una lista de secuencias mediante sus respectivos identificadores separados por comas o un intervalo de secuencias utilizando el formato x-y para introducir sus identificadores. Por ejemplo: "1, 3, 7, 13-20, 30-50".
- Cuando se importe un archivo en formato de varias secuencias, aparecerá la casilla de verificación “Select Range Sequence IDs” y, al marcarla, un cuadro con los identificadores de las secuencias contenidas en el archivo, así como con datos descriptivos de cada secuencia, incluidos el nombre de la secuencia, el tipo de molécula y el nombre del organismo. Se deberá indicar el intervalo de los identificadores de las secuencias que se deseen importar a la lista de secuencias del proyecto. Por defecto, se mostrará el intervalo correspondiente al número total de secuencias del archivo de lista de secuencias seleccionado.
- Los dos últimos tipos de formato de archivo aceptados en el proceso de importación de secuencias son los formatos RAW y FASTA. Esos formatos solo permiten definir una única secuencia por archivo. Cuando se selecciona un archivo RAW o FASTA para la importación, la herramienta mostrará el panel correspondiente, en el que se deberán rellenar los campos obligatorios.
- Si la importación se realiza correctamente, la herramienta mostrará la vista de informe de importación.
Insertar secuencia
Para insertar una secuencia en una posición específica de la lista de secuencias, hay que hacer clic en el botón “Insert Sequence”. Aparecerá una superposición con un panel de edición. Además de rellenar toda la información requerida para crear una secuencia, en la parte superior izquierda del panel se deberá introducir la posición en la que se desea que aparezca la secuencia en la lista de secuencias. Por último, se podrá hacer clic en los botones “Insert sequence” o “Insert & Display Sequence”.

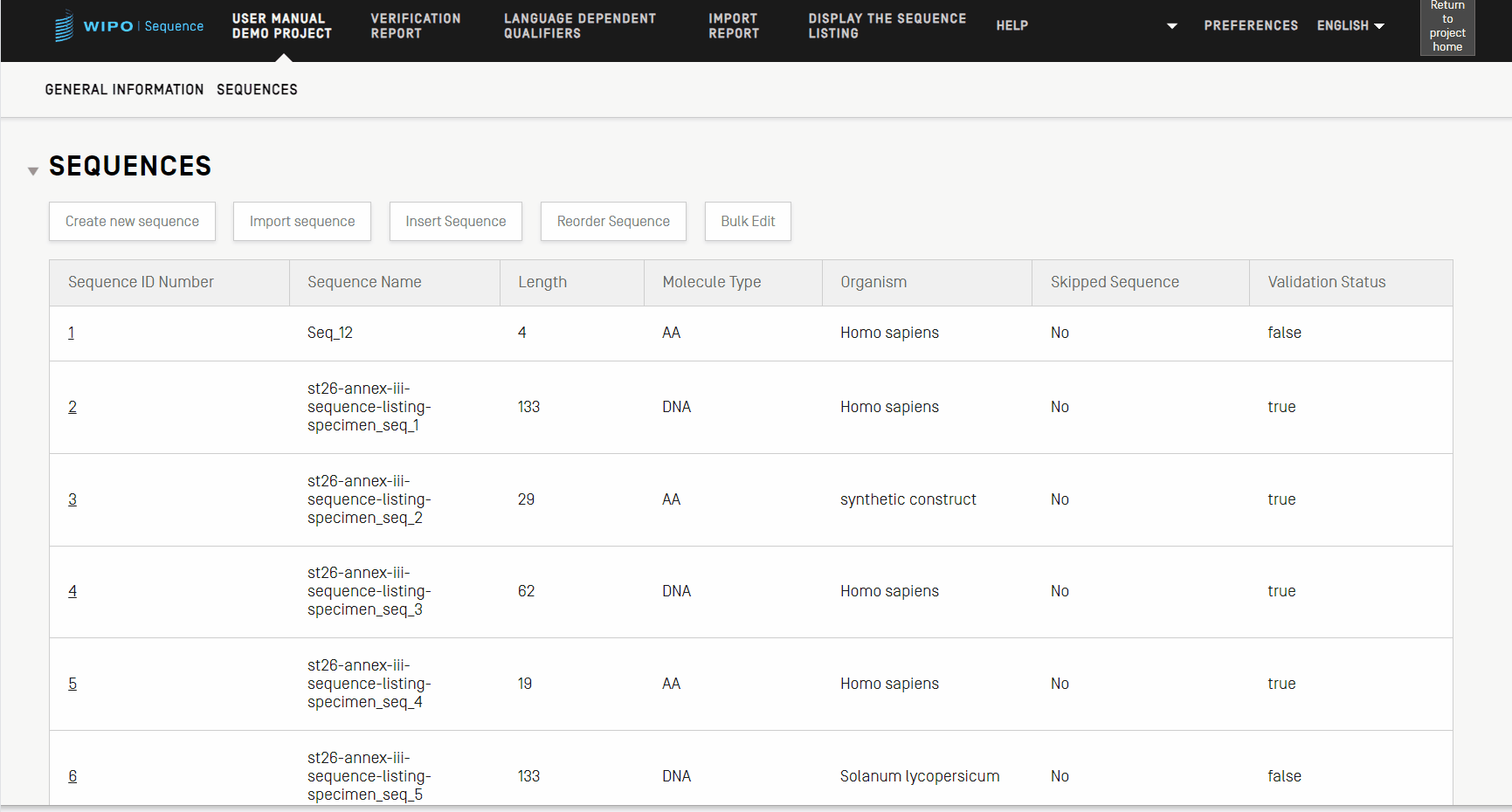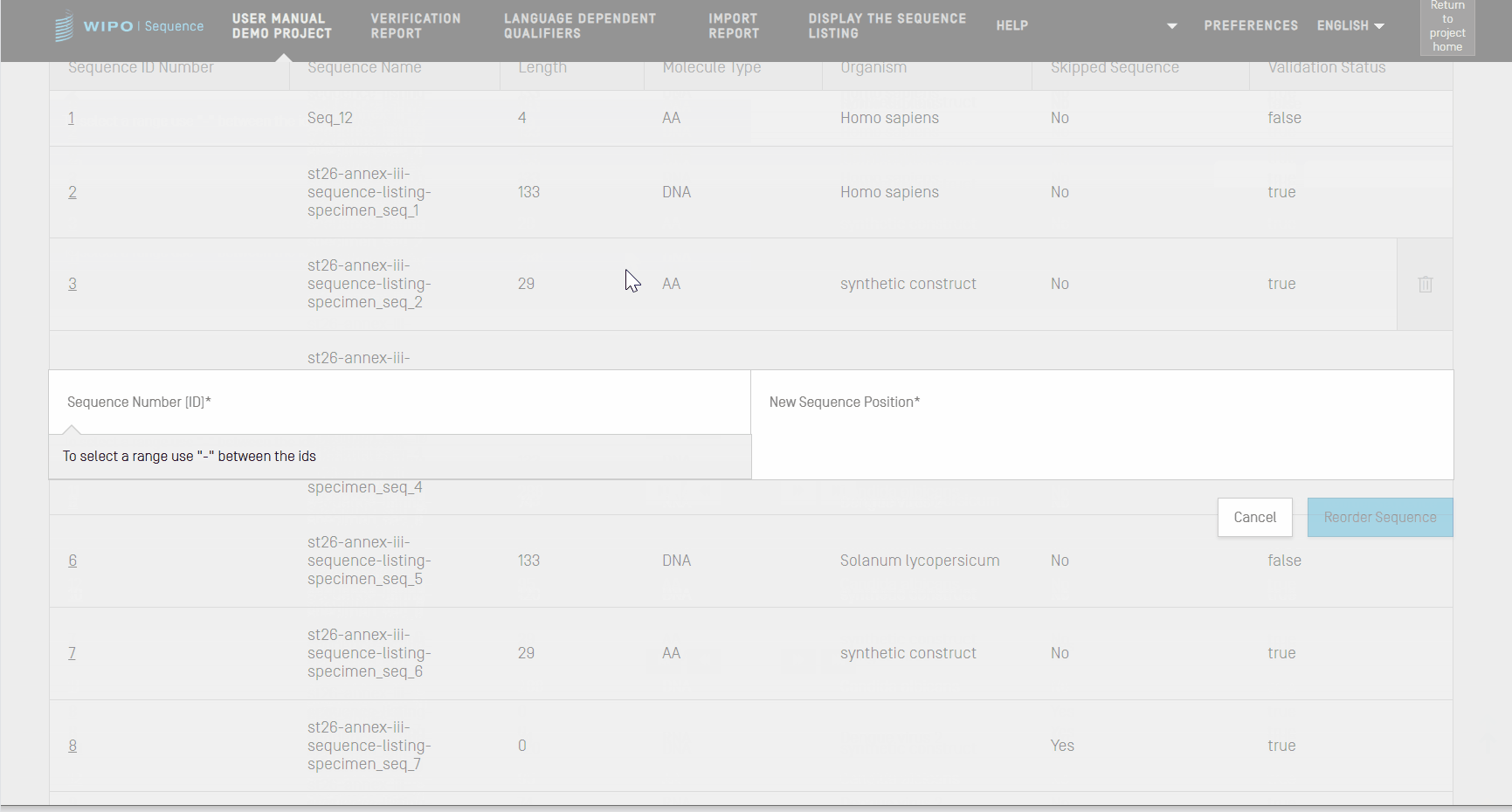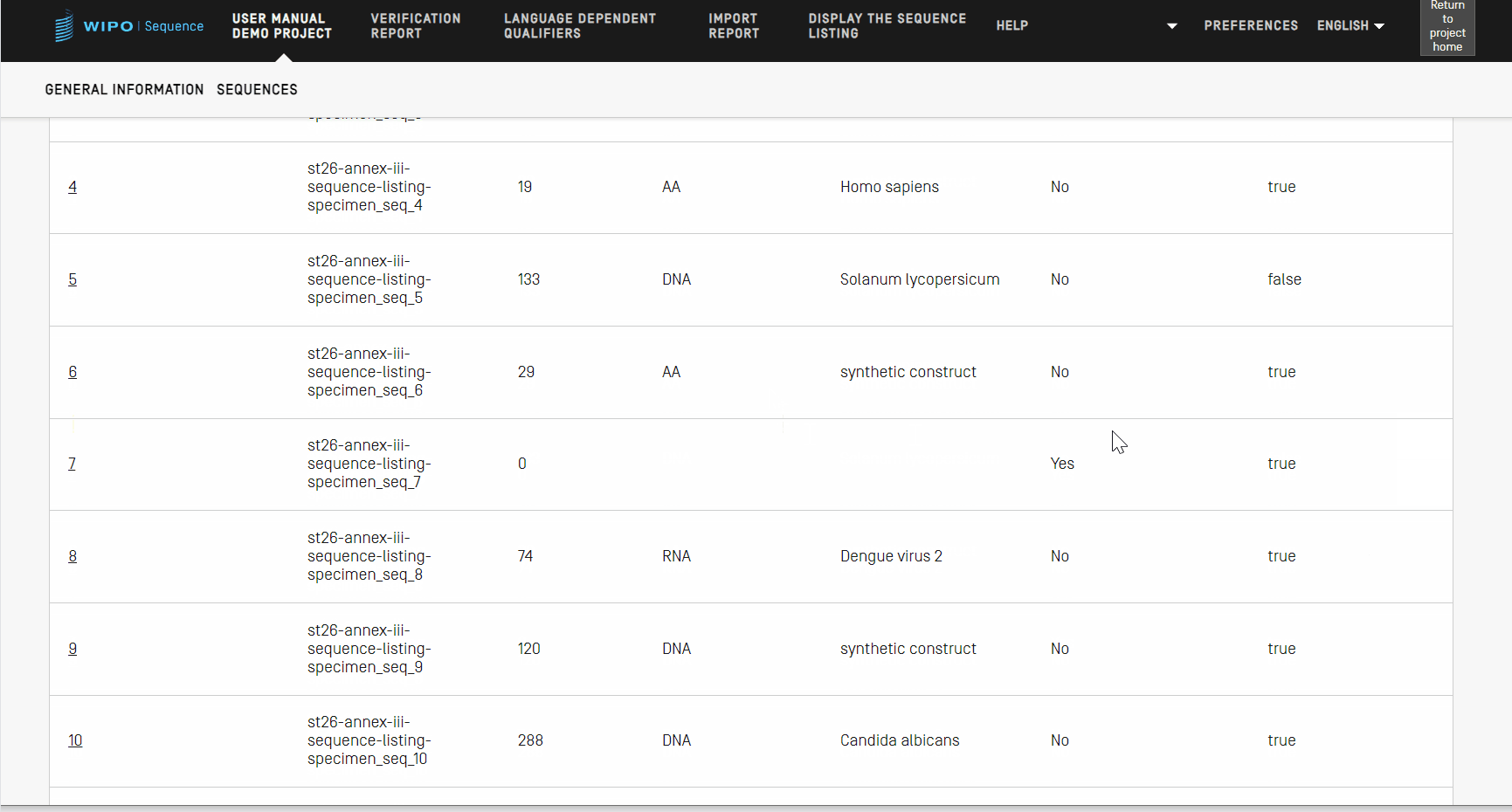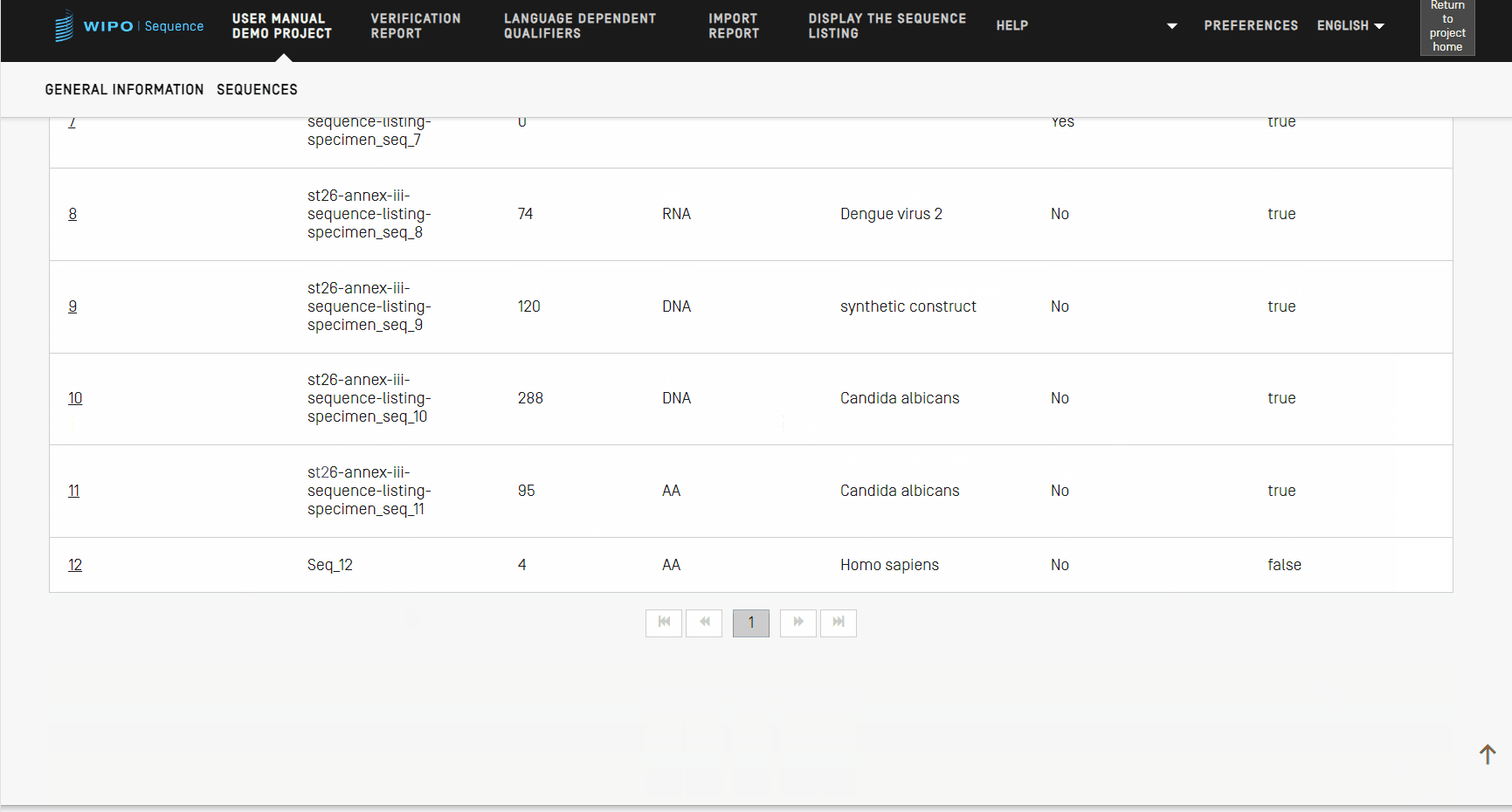
Reordenar secuencias
Se puede cambiar el orden de aparición de las secuencias dentro de la lista de secuencias de un proyecto según los pasos mostrados en el siguiente vídeo.
Edición masiva
Si bien es posible editar las secuencias una por una haciendo clic en el icono del lápiz, se puede utilizar la función de edición masiva cuando sea necesario realizar cambios en varias secuencias. Aunque se puede acceder a cada una de las secuencias y editarla, esta opción resultaría inviable para proyectos con un gran número de secuencias. Hay algunos campos que pueden ser objeto de edición masiva, según se indica a continuación:
- Para empezar, habrá que hacer clic en el botón “Bulk Edit”.
- Se deberá seleccionar el tipo de edición en el menú desplegable del campo “Type of bulk edit”.
- Si se selecciona "Qualifier molecule type", el sistema pedirá que se seleccione el tipo de secuencias de ácido nucleico a las que se aplicará la edición masiva. Además, el sistema avisa de que el calificador “mol_type” para las secuencias en las que el campo organismo tenga el valor “synthetic sequence” debe ser “other DNA” o “other RNA”, y que si se cambian esos valores se producirá un error en la validación del proyecto. Se mostrará una vista previa de las secuencias objeto de edición masiva con las características especificadas. Durante la edición, el sistema avisará de que SOLO se puede editar el valor del calificador “mol_type” para las secuencias de ácidos nucleicos (el sistema establece automáticamente el valor "protein" para las secuencias de aminoácidos).
- Si se selecciona “Organism”, habrá que introducir el intervalo de identificadores de las secuencias que se van a editar. A continuación, si se ha elegido modificar el valor del campo organismo por “synthetic construct”, el sistema avisará de que el calificador “mol_type” se cambiará automáticamente a “other DNA” o “other RNA” según el tipo de molécula de la secuencia (por ejemplo, ADN).
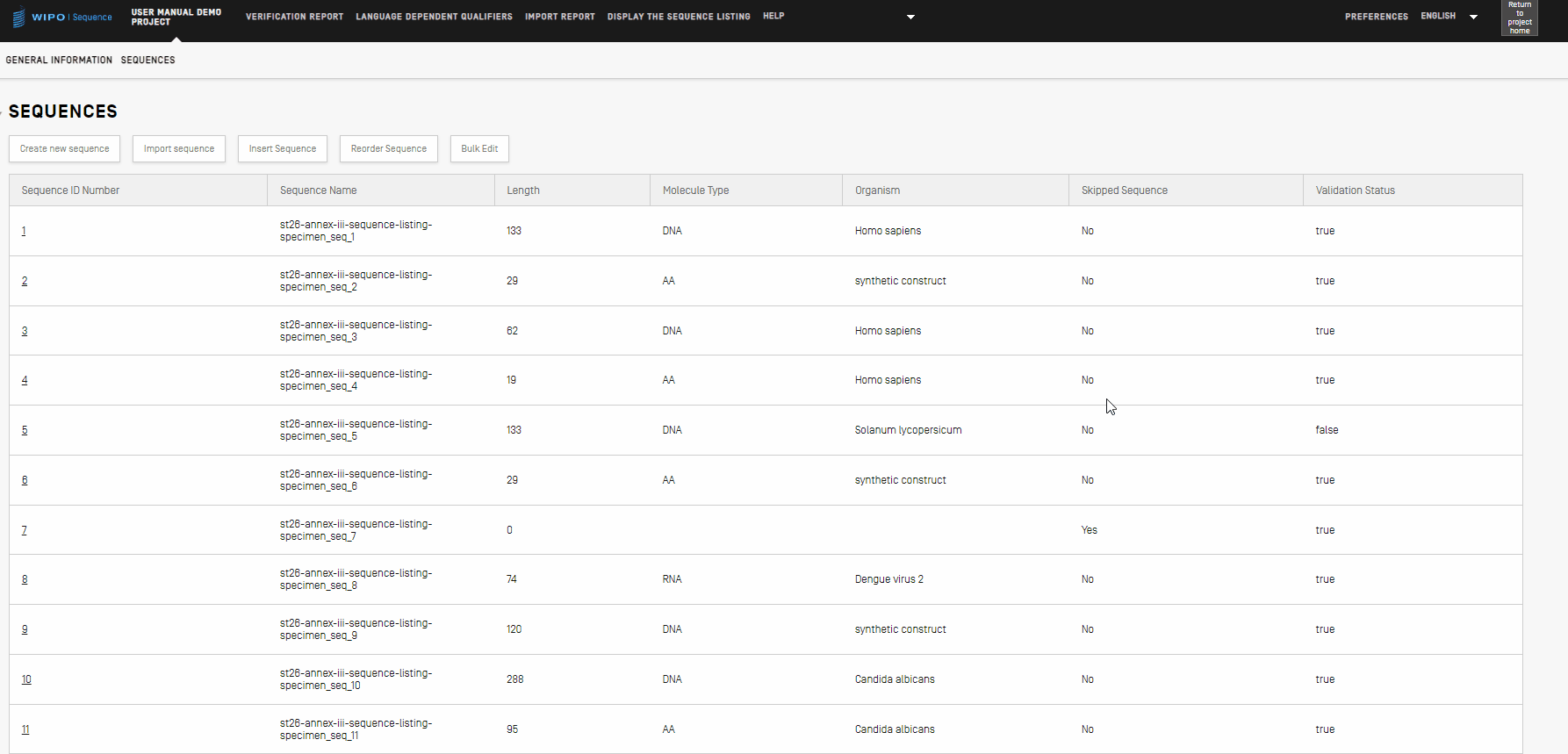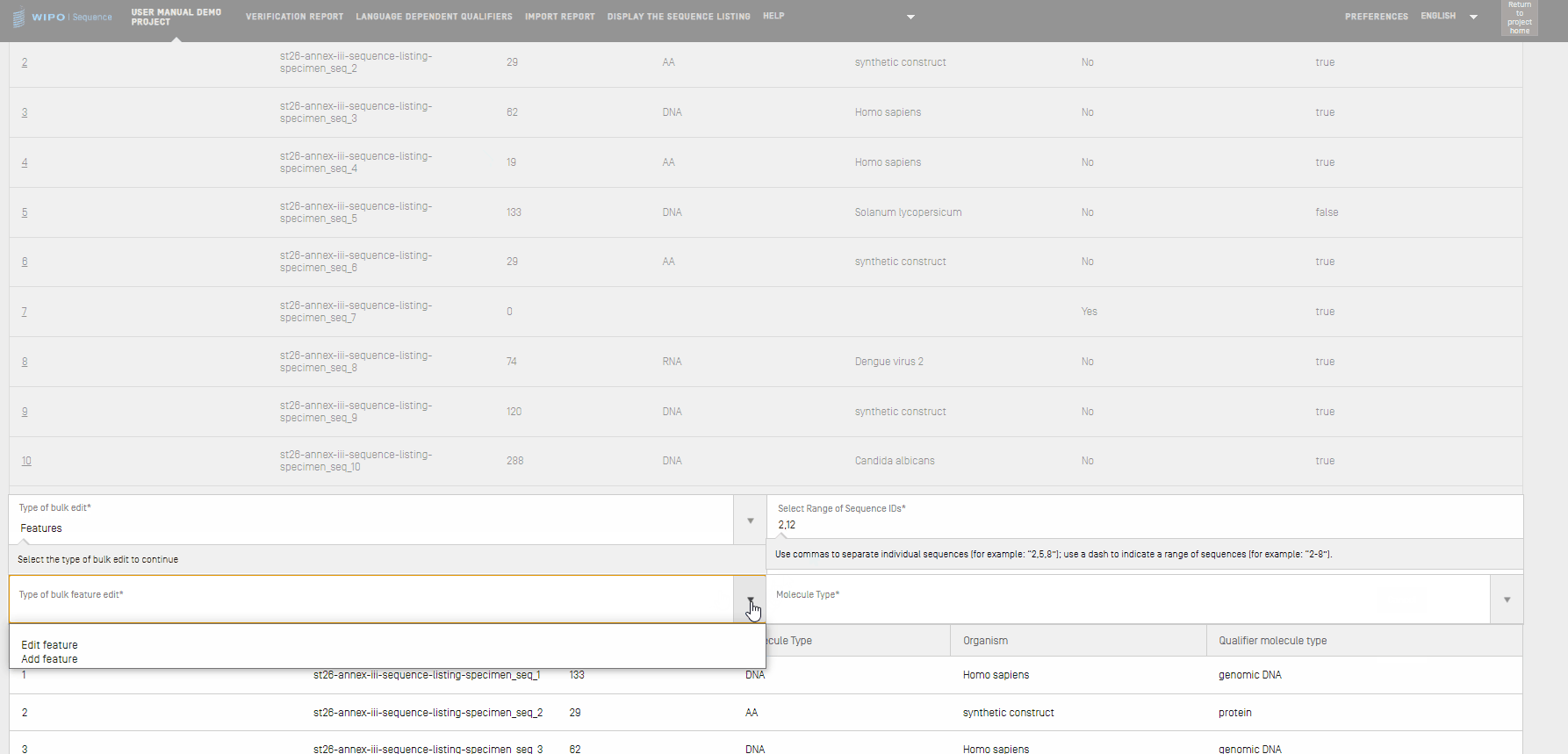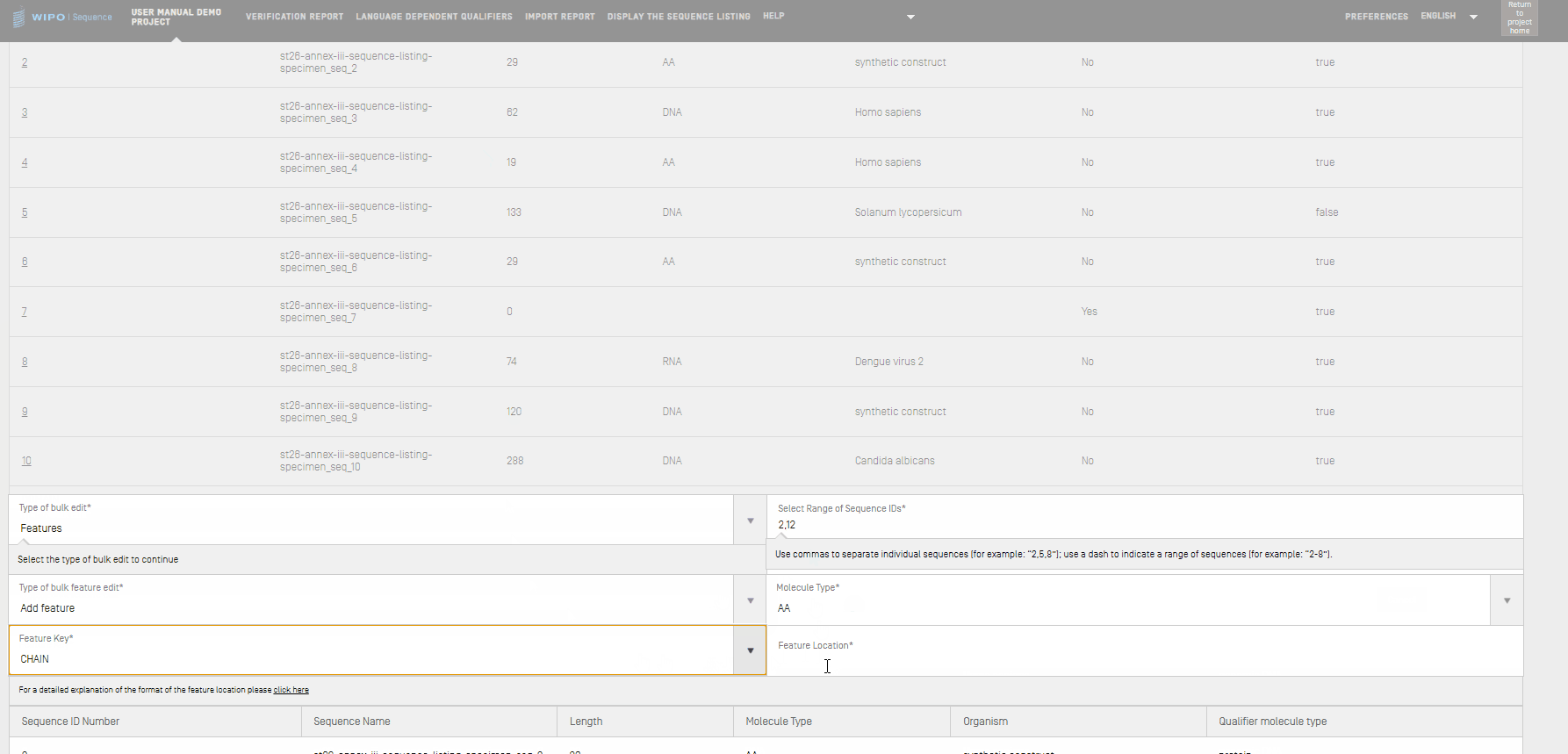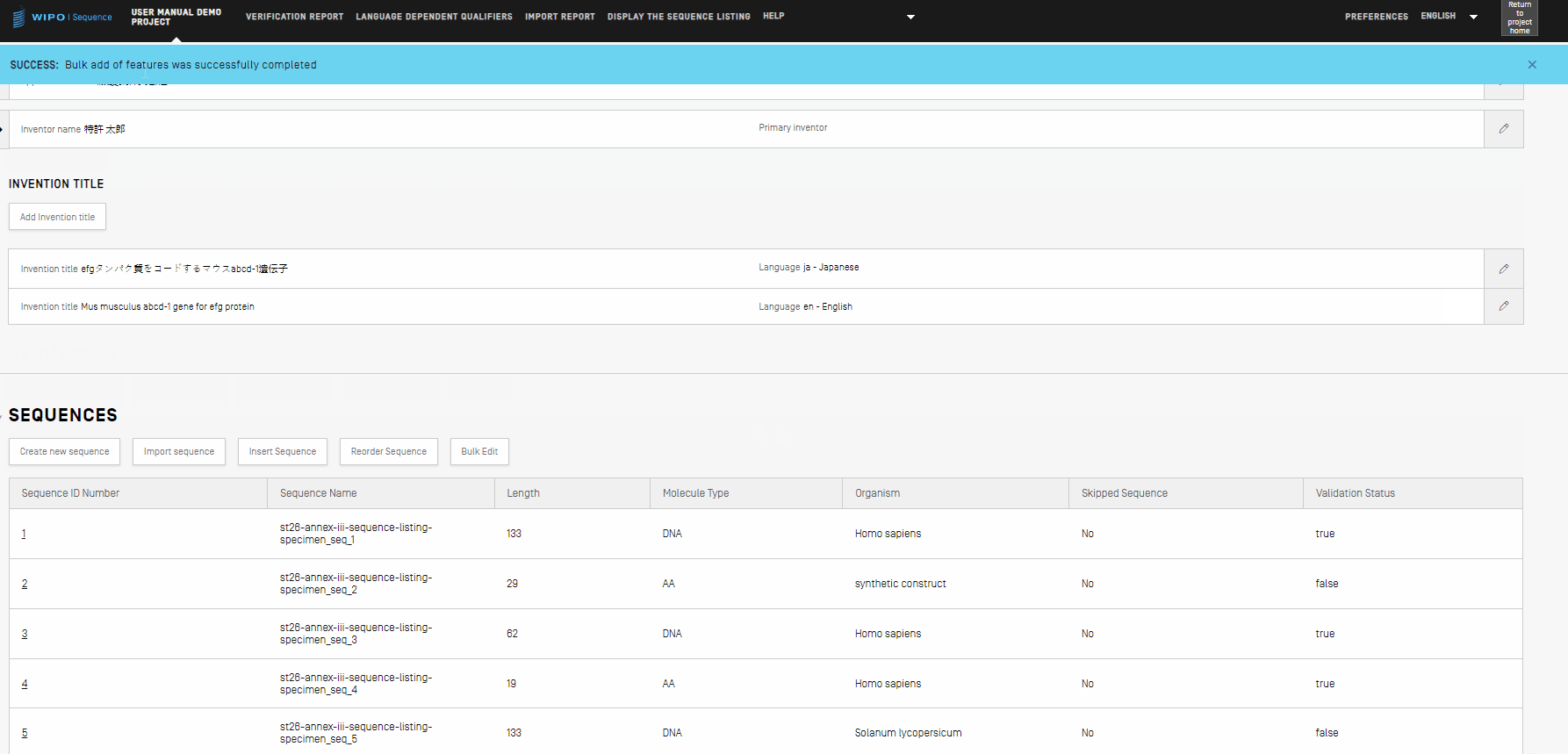
- Si se selecciona “Features”, se deberá especificar si se desea editar las características existentes o añadir otras nuevas. Habrá que introducir el “Molecule Type” y el intervalo de identificadores de las secuencias que se van a editar.
- Si se selecciona el tipo de edición masiva de características “Edit feature”, por ejemplo para modificar el valor de la localización de la característica "CDS" por “complement(join(1..30,61..90))”, se debe empezar introduciendo en el cuadro de texto “Select Range of Sequence IDs” los identificadores de secuencia, el “Molecule Type”, y la “Feature Key” correspondiente y su “Feature Location”. Para terminar, habrá que hacer clic en “Edit sequences”.
- Si se selecciona el tipo de edición masiva de características “Add feature”, por ejemplo para añadir una nueva característica “CHAIN” con la localización de la característica “1..4”, se deberá empezar introduciendo en el cuadro de texto “Select Range of Sequence IDs” los identificadores de secuencia, el “Molecule Type”, y la “Feature Key” correspondiente y su “Feature Location”.
- Si se selecciona “Bulk skip”, habrá que introducir, en el cuadro de texto “Select Range of Sequence IDs”, el intervalo de identificadores de las secuencias que se desea omitir.
- Si se selecciona “Bulk delete”, habrá que indicar, en el cuadro de texto “Select Range of Sequence IDs”, el intervalo de secuencias que se desea eliminar.
- Siempre que se realice una edición masiva, tras hacer clic en el botón “Edit sequences”, la herramienta mostrará un mensaje sobre fondo azul para indicar que se ha llevado a cabo correctamente. En el siguiente vídeo se muestra un ejemplo.
Introducir datos de características
De acuerdo con la Norma ST.26 de la OMPI, toda secuencia DEBE tener asociada al menos una característica “source”. Cada característica “source” debe tener dos calificadores obligatorios: “organism” y “mol_type”.
El cuadro de características tiene tres columnas: la clave de caracterización, la localización de la característica dentro de la secuencia genética y los calificadores asociados a la característica de la secuencia.
La localización de la característica indica el segmento de la secuencia al que corresponde la característica. Los formatos permitidos para especificar la localización de la característica se establecen en la Norma ST.26 de la OMPI y son los siguientes:
- Número único de residuo: x
- Números de residuos que delimitan un segmento de secuencia: x..y
- Residuos antes del primer, o después del último, residuo especificado: <x, >x, <x..y, x.>y, <x..>y
- Un sitio entre dos nucleótidos adyacentes: x^y
- Números de residuo unidos por un enlace cruzado entre cadenas: x..y
Los operadores de localización pueden utilizarse para formar descriptores de localización complejos:
- “join (location, location, … location)”: Las localizaciones indicadas están unidas (colocadas extremo con extremo) para formar una secuencia contigua.
- “order (location, location, … location)”: Los elementos se encuentran en el orden especificado, pero no se proporciona información que permita determinar si la unión de esos elementos es razonable.
- “complement (location)”: Indica que la característica está localizada en la cadena complementaria al segmento de la secuencia especificado por el descriptor de localización, cuando se lee en el sentido de 5’ a 3’ o en el sentido que imite el sentido de 5’ a 3’.
Para añadir una nueva característica a la secuencia, hay que hacer clic en el botón “Add feature” en la sección Características de la secuencia seleccionada. En esta fase también se pueden añadir calificadores a la característica, como se explicará en la sección siguiente.
Características "CDS"
Las características "CDS" se utilizan para describir la secuencia de codificación de una proteína. Una característica "CDS" puede incluir opcionalmente la traducción en aminoácidos del segmento de la secuencia al que pertenece. Si esa traducción cumple el requisito de longitud mínima, aparecerá como una secuencia separada dentro del proyecto. Dentro de la característica "CDS" de la secuencia original, en el calificador "protein_id" hay una referencia al identificador de la secuencia de aminoácidos traducida.
Cuando se crea una característica "CDS" para una secuencia, se puede añadir automáticamente a dicha característica el calificador “translation” (con la utilización por defecto de 1 – “Standard Code” como código genético) con un valor correspondiente a la traducción del segmento de residuos de la secuencia indicado en la localización de la característica. También se puede generar el calificador asociado “protein id” y una secuencia de aminoácidos independiente marcando la casilla de verificación correspondiente en la sección Información básica, situada en la parte superior de la vista de datos del proyecto. No obstante, este calificador no es obligatorio y puede eliminarse. Además, se puede crear manualmente un calificador “translation” y un calificador “protein_id” vinculados al identificador de la secuencia traducida asociada también creada.
Nota: A partir de la versión 2.1.0, la casilla de verificación “Automatically add a translation qualifier” está marcada por defecto.

Los pasos para crear automáticamente un calificador de caracterización “CDS” son los siguientes:
- En la vista de la secuencia en cuestión, hay que hacer clic en el botón “Add feature” y seleccionar “CDS” como clave de caracterización. Si la casilla de verificación “Automatically add a translation qualifier” en la sección Información general está marcada, se añadirá automáticamente un calificador "translation", su valor, y un calificador "protein_id" y su secuencia de aminoácidos asociada por separado (si procede) cuando se agregue una característica "CDS" a una secuencia de nucleótidos.
- También se puede crear manualmente un calificador "translation".
- Cuando se termine de editar la característica y sus calificadores asociados, se deberá hacer clic en el botón “Create Feature” para guardarla. Se mostrará la característica "CDS" resultante asociada a la secuencia.
Si el valor del calificador "translation" cumple el requisito de longitud mínima, la herramienta crea una nueva secuencia en el proyecto con los siguientes atributos:
- Identificador de secuencia = el siguiente número disponible para identificar la secuencia.
- Longitud = longitud de la secuencia traducida.
- Nombre de la secuencia = el valor indicado en el campo “Sequence Name” del calificador “translation”. Si no se proporciona ningún nombre, se asignará a la secuencia un nombre por defecto ("Seq_#").
- Tipo de molécula = “AA”.
- Nombre del organismo = el mismo valor proporcionado para la secuencia original.
- Calificador del tipo de molécula = “protein”.
- Residuos de la secuencia = valores traducidos de la secuencia original.
Nota relativa a la creación de la secuencia traducida: la secuencia traducida se crea por separado solo si tiene al menos cuatro residuos definidos específicamente (por ejemplo, “AXTG” es una secuencia de tres caracteres). Si se modifica el calificador “translation” y su nuevo valor tiene menos de cuatro residuos definidos específicamente, se eliminará la traducción de la secuencia asociada, así como el calificador “protein_id”.
Recomendaciones sobre las características "CDS" cuando se incluye un calificador "pseudo" o "pseudogene"
Conviene comprobar que la traducción automática esté desactivada cuando se añada un calificador "pseudo" o "pseudogene" a una característica "CDS". Si no se desactiva la traducción automática al añadir un calificador "pseudo" o "pseudogene" a una característica "CDS", cuando se actualice dicha característica se incluirá automáticamente un calificador "translation". Para corregir ese error, hay que desactivar la traducción automática en el proyecto, abrir la característica "CDS", eliminar los calificadores "translation" y "protein_id" y actualizar la característica.
Si se desea generar automáticamente el calificador “translation”, podrá establecerse en el panel de edición del calificador el valor de la tabla del código genético que deberá utilizarse para traducir y el nombre de la secuencia. Cuando se cree la característica, la herramienta realizará la traducción y añadirá el calificador “protein_id” a la característica y una nueva secuencia con el valor de la traducción.
La traducción se realizará de nuevo, solo si la localización de la característica o uno de los calificadores “transl_table”, “transl_except” o “codon_start” cambia su valor, en cuyo caso se actualizará la secuencia asociada.
Nota: Si se modifica el valor del calificador “translation”, se actualizará automáticamente el valor de la secuencia asociada. Sin embargo, si se modifica la secuencia de nucleótidos asociada, el valor del calificador “translation” no cambiará. Si el calificador “protein_id” se modifica después de la creación de la característica, la secuencia dejará de estar vinculada a la secuencia original.
Recomendaciones sobre el uso del codón de terminación
Normalmente, los codones de terminación solo deberían encontrarse al final de una característica "CDS", para marcar el final de la secuencia de aminoácidos codificada. No deberían encontrarse nunca en medio de una característica "CDS” a menos que haya un calificador “transl_except” que indique que el codón de terminación debe traducirse a un aminoácido en particular.
Si se encuentra un codón de terminación en medio de una característica "CDS" (resaltado en amarillo más abajo), y no hay un calificador "transl_except" que indique que dicho codón de terminación debe traducirse en un aminoácido en particular, entonces la herramienta debería detener la traducción en ese punto y mostrar un mensaje sobre fondo rojo para informar de que no se generará ninguna traducción.
Asimismo, debería aparecer un error en el informe de validación, para advertir de que hay un problema con la secuencia codificadora.
Introducir datos de calificadores
Los calificadores se utilizan para proporcionar información sobre las características además de la transmitida mediante la clave de caracterización y la localización de la característica. Hay tres tipos de formatos de valor para representar los distintos tipos de información transmitida por los calificadores:
- Texto libre
- Vocabulario controlado o valores enumerados (por ejemplo, un número o una fecha)
- Secuencias
Para ver los calificadores de una característica, se deberá seleccionar la característica en el cuadro de características de la secuencia en cuestión y, a continuación, hacer clic en el icono del lápiz, lo que abrirá una superposición.
Se podrán editar los calificadores existentes haciendo clic en el icono del lápiz situado a la derecha de cada fila, o se podrá añadir un nuevo calificador a la característica seleccionada haciendo clic en el botón “Add qualifier”.
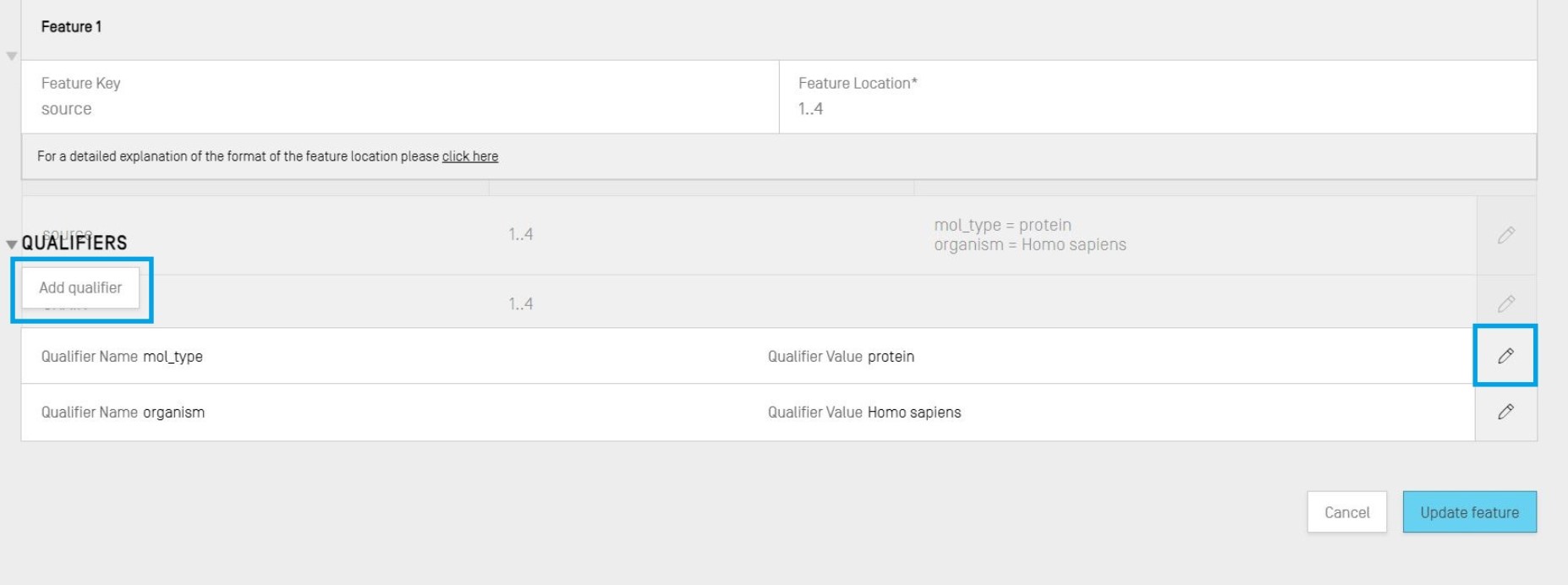
Cuando se edita o añade un calificador, se muestran dos campos: el “Qualifier name” (que se selecciona en un menú desplegable) y el “Qualifier value”.
El campo “Qualifier value” se mostrará de forma diferente en función del tipo de calificador:
- Calificadores con valores predefinidos: el campo consta de un menú desplegable en el que se puede seleccionar uno de los valores predefinidos para el calificador.
- Calificadores con valores de texto libre: el valor del campo tiene formato de texto libre. Además del "Qualifier Name" y el "Qualifier Value", que solo pueden introducirse en inglés, aparecen otros dos campos que permiten introducir tanto el código de idioma (por ejemplo, "ru") como el valor del idioma correspondiente en el valor del calificador en idioma distinto del inglés. Al campo de código de idioma se le asigna el mismo valor que al campo “Non-English free text language code” que aparece en la sección de datos del proyecto. Se puede proporcionar una serie de valores en idioma distinto del inglés respecto de cada idioma seleccionado, ya sea introduciéndolos manualmente o importándolos en el idioma asociado desde un archivo XLIFF.
- Calificadores con formato predefinido: el valor del campo tiene formato de texto libre, pero el valor que se introduce es sometido a una prueba de validación para garantizar que se ajuste a las normas pertinentes establecidas en la Sección 6 del Anexo I de la Norma ST.26 de la OMPI.
- Calificadores sin valor permitido: el campo “Qualifier value” no es editable.
Se deberá hacer clic en el botón azul “Create Qualifier” para añadir el calificador recién creado, o en “Save” para guardar los cambios realizados en el calificador existente. Por último, una vez añadido o modificado el calificador, habrá que hacer clic en el botón “Update feature”, situado en la parte inferior de la superposición.
2.3 Vista de personas y organizaciones
En esta vista se gestiona la información de las personas y organizaciones guardada localmente.
Crear un registro de persona u organización
Para añadir una persona u organización nueva, hay que acceder a la vista de personas y organizaciones. Habrá que hacer clic en el enlace “CREATE NEW PERSON OR ORGANIZATION”, situado en la parte superior de la vista, como se muestra a continuación:

En la vista siguiente, se deberá rellenar al menos los campos obligatorios (indicados con un asterisco, "*") correspondientes a los datos de la persona u organización en cuestión. En el caso del solicitante o inventor, se trata únicamente del nombre (si se facilita en caracteres latinos) y del idioma.
Si el nombre de la persona u organización no se escribe con caracteres latinos, deberá introducirse su versión latinizada en el campo “Name Latin”. Si no se introduce, el proyecto no se validará dado que no se generará ni validará la lista de secuencias en formato ST.26.
2.4 Vista de organismos personalizados
Para crear, editar, importar, exportar o eliminar un organismo personalizado, habrá que acceder a la vista de organismos.
Crear organismo personalizado

Para introducir un nuevo organismo personalizado, habrá que hacer clic en el enlace “CREATE NEW ORGANISM” situado en la parte superior de la vista. En la siguiente ventana, se introducirá el nombre del nuevo organismo y se hará clic en “Save”. Si se requiere una descripción del organismo personalizado, puede añadirse opcionalmente como se muestra en el ejemplo. Para editar la información, hay que hacer clic en el nombre del organismo.
Exportar organismo personalizado
Todos los organismos personalizados y su descripción almacenados en la herramienta pueden exportarse y guardarse en un archivo de texto de modo que la lista de organismos pueda modificarse fuera de la herramienta o importarse posteriormente. Para exportar dicha lista, en primer lugar, habrá que hacer clic en el enlace “EXPORT CUSTOM ORGANISMS”, que aparece marcado a continuación.

A continuación, se abrirá un cuadro de diálogo en el que se podrá asignar un nombre al archivo y elegir su ubicación.

El archivo que se exporta es un archivo de texto que incluye tanto el nombre como la descripción del organismo y que puede editarse e importarse a la herramienta. Descargar un ejemplo.
Importar organismo personalizado

Para importar una lista de organismos personalizados, en primer lugar, habrá que hacer clic en el enlace “IMPORT CUSTOM ORGANISMS” situado en la parte superior de la vista de organismos. Aparecerá una superposición debajo del cuadro resumen de organismos personalizados.
- Se deberá hacer clic en el botón “Upload file [.txt]”.
- Se seleccionará en el cuadro de diálogo que se abre el archivo de los organismos personalizados.
- Y, por último, se hará clic en el botón azul “Import Custom Organisms”.
Nota: El archivo que se desee importar deberá ser un archivo de texto (*.txt) que contenga una lista de nombres de organismos personalizados en formato de texto simple (UTF-8), con un nombre por línea.
2.5 Vista de preferencias del sistema
La vista de preferencias del sistema permite modificar varios parámetros de configuración de WIPO Sequence. Los valores establecidos para dichos parámetros se aplicarán a todos los proyectos creados o editados con la herramienta.

Si se desea modificar las preferencias del sistema, hay que hacer clic en el icono del lápiz que se muestra en la parte superior para abrir el panel de edición.

Los parámetros de configuración que se pueden modificar en la vista de preferencias del sistema son:
- El número máximo de símbolos de residuos que se mostrarán: Este parámetro establece el número de residuos que se mostrarán por fila cuando se visualice una secuencia. El valor preestablecido es 60.
- La ubicación preestablecida donde se generará el archivo XML de la lista de secuencias en formato ST.26. No es obligatorio especificar una ubicación.
- El número máximo de secuencias que se imprimirán: Para imprimirlas todas se debe dejar en blanco. El valor por defecto es 1 000.
- El número máximo de residuos que se imprimirán: Para imprimirlos todos se debe dejar en blanco. El valor por defecto es 1 200.
- El código de idioma de texto libre de origen: Si la correspondiente casilla de verificación está marcada, se mostrará una advertencia durante la validación si no se proporciona el código de idioma de texto libre de origen. Por defecto, no está marcada.
- La casilla de verificación XQV_49: Si se marca, se mostrará una advertencia si no hay un valor en inglés para el calificador proporcionado de texto libre dependiente del idioma. Por defecto, no está marcada.
- El idioma preestablecido de la interfaz: Se trata del idioma en que se mostrará la interfaz cuando se inicie WIPO Sequence. Por defecto, es el inglés.
Nota: Los parámetros tercero y cuarto son relevantes cuando se imprime el proyecto en formato PDF. Si la lista de secuencias es muy larga, el PDF obtenido podría tener varios miles de páginas y su visualización resultaría inviable.
3. Formato de archivo
Formato de la Norma ST.25 de la OMPI
Puede consultarse información detallada sobre el formato de archivo conforme con la Norma ST.25 de la OMPI en dicha Norma.
En el Anexo III de la Norma se proporciona un ejemplo.
Formato RAW
Con el formato RAW solo se puede describir una secuencia. Se escribe simplemente el código genético, sin incluir información adicional. El tipo de molécula, las características y el nombre tendrán que ser añadidos mediante la herramienta una vez importada la secuencia.
Ejemplo:
aggatatagatagtatatgatagtatgatatgatgatgtatgtatagtgtagttatga
Formato de varias secuencias
El formato de varias secuencias puede servir para describir una o varias secuencias, junto con su nombre, el tipo de molécula y el nombre del organismo. Es uno de los formatos permitidos para la importación mediante "PatentIn". La primera línea de texto que no está en blanco es la cabecera e incluye los siguientes componentes:
<SequenceName; SequenceType; OrganismName>
WIPO Sequence interpretará la información de la cabecera como se indica a continuación:
| Entrada de cabecera | Entrada permitida | Se interpreta como |
|---|---|---|
| Nombre de la secuencia | Nombre de la secuencia (texto libre) | Nombre de la secuencia en el archivo de proyecto de la OMPI (no formará parte del archivo XML) |
| Tipo de secuencia | Uno de los siguientes:
|
mol_type En función de la entrada de organismo, se puede solicitar que se defina el mol_type de ADN o ARN (Norma ST.26, párrafos 75 a 84). |
| Nombre del organismo | Nombre del organismo (texto libre) | Nota sobre la fuente/organismo: si la entrada es "synthetic construct", se asignará automáticamente a mol_type de ADN o ARN el valor "other DNA" u "other RNA" (Norma ST.26, párrafo 84.a)). |
La secuencia comienza en la línea que sigue a la cabecera. Cada secuencia nueva debe comenzar en una nueva línea en el archivo, después del final de la secuencia anterior. Puede haber una o varias líneas en blanco entre el final de una secuencia y la siguiente cabecera. Las secuencias de aminoácidos deben expresarse en código de una letra (Norma ST.26, Anexo I, sección 3, cuadro 3). Los símbolos de nucleótidos permitidos figuran en el cuadro 1 de la sección 1 del Anexo I de la Norma ST.26. Conviene tener en cuenta que el símbolo "u" de las secuencias de ARN no se cambiará automáticamente a "t", de conformidad con los párrafos 14 y 19 de la Norma ST.26, sino que habrá que hacer el cambio manualmente después de la importación. Se recomienda convertir "u" en "t" antes de importar un archivo en formato de varias secuencias que contenga secuencias de ARN.
A continuación se muestra un ejemplo de un grupo de tres secuencias definidas en formato de varias secuencias.
Ejemplo:
<First Sequence; RNA; Albies alba> uuuucuuauuguuucuccuacugcuuaucauaaugauugucguaguggcuuccucaucgucucccccaccgccuaccacaacgacugccgcagcggauuacuaauaguaucaccaacagcauaacaaaaagaaugacgaagaggguugcugauggugucgccgacggcguagcagaaggaguggcggagggg
<Second Sequence; DNA; synthetic construct> attgacgtcagtgacgcggtactgacgtcagctgcagtactgacgtaccaaccacgtggtgagctctcgacatgcaactgactcgtcgctattgacgtcagtgacgcggtactgacgtcagctgcagtactgacgtaccaaccacgtggtgagctctcgacatgcaactgactcgtcgctcagt
<Third Sequence; AA; Mus musculus>
SPPGKPQGPPPQGGNQPQGPPPPPGKPQGPPPQGGNRPQGPPPPGKPQGPPPQGDKSRSPR
Formato FASTA
En este formato se incluyen residuos y una descripción. Durante la importación, se puede guardar la descripción como un calificador de nota.
Ejemplo:
AJ011880.1 Artificial oligonucleotide sequence SSR primer (CAC13R)
CTCAACAATCTGAAGCATCG
4. Solución de problemas
WIPO Sequence ofrece una función de ayuda, a la que se puede acceder desde el menú superior.
- Las opciones de ayuda proporcionan:
- Un enlace al Manual de uso
- Un enlace a la base de conocimientos de la Norma ST.26
- Un enlace al formulario de contacto del equipo de asistencia de WIPO Sequence
- Un enlace a la última versión de la Norma ST.26 de la OMPI
- Información básica sobre la versión de la herramienta de escritorio WIPO Sequence.
Problemas comunes y soluciones
El informe de importación o el informe de validación indica que el proyecto contiene varios identificadores de calificador para una misma característica.
Solución: Eliminar la característica que incluye un identificador de calificador duplicado. Crear de nuevo la característica en la misma ubicación, pero sin añadir el calificador antes de guardarla. A continuación, editar la característica para añadir el calificador pertinente y actualizar la característica.
El nombre de archivo sugerido no es compatible con la distribución Linux.
Se ha detectado un problema cuando se utiliza la distribución Linux: aparece de manera automática en el nombre de archivo sugerido un carácter "\" que sobra. Para solucionarlo, hay que eliminar ese carácter antes de guardar el archivo.
Consúltense otras respuestas en la base de conocimientos de WIPO Sequence
Aparece un mensaje de error al intentar visualizar la lista de secuencias en formato HTML
Si el tamaño del archivo XML de la lista de secuencias generado es superior a 100 Mb, en lugar de mostrarse la lista de secuencias en formato HTML aparece un mensaje de error que indica que la lista de secuencias ocupa demasiado espacio para mostrarse en formato HTML.
Se puede realizar cualquier otra consulta a través del formulario de contacto.